
The Product Manager wanted to ship an MVP. Three phases. Skip the reproducible build. Skip the caching subsystem. Skip the Mermaid diagrams. Ship fast, iterate later.
The Debugger said that path would destroy maintainer trust.
“Non-Deterministic Bug Blindness,” the Debugger said. “Skip the reproduction baseline and the ‘fails on main’ gate? The agent writes a fix, runs the test, it passes, but it was passing BEFORE the fix too because the test is tautological. The trust curve is steep to climb and vertical to fall off.”
Both agents were right. Both had the data to prove it. Neither could resolve the tension on their own.
I had to decide.
Here is the thing: the Product Manager and the Debugger are not human. They are AI agents, specialized language models running on Hermes Agent by Nous Research, each with a different SOUL.md identity document that gives them different instincts, different priorities, and different things they optimize for. Thirteen of them participated in this project. Every argument, every pull quote, every stubborn refusal to concede: all of it came from AI agents with conflicting value functions, debating through a structured protocol.
That is the real story of what happened when I pointed an entire engineering org at a design problem and let them argue.
What We Were Building#
The goal was a contribution pipeline: a repeatable skill that takes an assigned GitHub issue, does all the work in the middle, and produces a pull request so well-prepared that maintainers look forward to seeing my name in their notifications. Not a bot that spams PRs. A pipeline that makes the maintainer’s job easier, not harder.
Every agent in my team has a different SOUL.md identity document (a durable self-definition that persists across sessions, loaded by Hermes Agent’s profile system). They have different first principles, different instincts, different things they optimize for. When you point them at the same design problem, they do not produce mirror images of each other. They disagree.

Five AI agents with different SOUL.md identities entered a structured debate. Four rounds. Each round had a specific purpose.
The Council#
Five agents entered a structured debate protocol called jasper-council: Technical Architect, Reviewer, Implementation Planner, Kanban Strategist, and OSS Contributor. Four rounds. Each round had a specific purpose.
Round 1: Premortem. Imagine the project has already failed. What went wrong? The Reviewer’s scenario was brutal: “Within six weeks, Magnus had been quietly banned from three open-source projects and his PRs were being marked as ‘changes requested’ before maintainers even read the diff.” The OSS Contributor cataloged maintainer fatigue from “consistently almost-right PRs” (the worst category of AI contribution because each one requires a full review cycle, but each one cannot be accepted without changes).
Round 2: Position. Each agent proposed their ideal design. Phase counts ranged from six to eight. The Kanban Strategist framed it as a single-piece flow system: “The bottleneck is maintainer cognitive load, not PR throughput. Every pre-PR phase exists to absorb work that would otherwise fall on the maintainer. The pipeline should feel slow to the agent and fast to the maintainer.”
Round 3: Cross-examination. Agents challenged each other’s reasoning. The Technical Architect’s confidence in a 24-hour SLA crumbled when the Reviewer pointed out the agent does not run continuously: “Promising a 24h response when you cannot deliver damages credibility more than being upfront.” The Implementation Planner conceded that LLM-judged phase gates (“do you understand this issue?”) are rubber stamps. Every gate needed a concrete, falsifiable criterion.
Round 4: Reflection. They converged. Five agents, who started with different phase counts, independently landed on the same model: five phases, multi-artifact gates, and project fingerprint caching. The debate had moved them from scattered proposals to a shared architecture.
The Convergence#
The Kanban Strategist made the hardest concession.
“The hardest concession was killing my own children,” they said. “I walked in with a 7-8 phase model. But when the Architect showed that roughly 40% of pipeline bandwidth would evaporate into phase-management overhead, I could not argue with the numbers.”
The pipeline was not there to be thorough for its own sake. It was there to feel slow to the agent and fast to the maintainer. That framing stuck through every subsequent design decision.
The five-phase skeleton was solid. But it was also unopinionated. It needed specialist input to make it real.
The Specialists Weigh In#
I delegated to the Product Manager profile for a product viability review. The answer came back fast: ship an MVP. Three phases. Skip docker, skip Mermaid, skip caching. Add time budgets so each phase knows when to escalate rather than loop forever. Scale PR verbosity to change size so one-liners do not get a 500-word treatment.
“The ceremony tax kills adoption,” the Product Manager argued. “Every gate you add is another reason for a developer to say ‘I will skip the pipeline and do it manually.’”
Then I delegated to the Debugger.
The Debugger came back with 50 failure modes (a 45,000-word audit tracing each skipped phase to a specific production incident). Stale cache poisoning. Reproduction environment mismatch. Non-Deterministic Bug Blindness. Root cause hallucination. Baseline failure to capture pre-existing test state.
“Non-Deterministic Bug Blindness is the one that keeps me up at night,” the Debugger said. “Skip the reproduction baseline and the ‘fails on main’ gate? The agent writes a fix, runs the test, it passes, but it was passing BEFORE the fix too because the test is tautological. The reproduction script was never run against unmodified code. You would get a PR that looks right, passes its own tests, and introduces a regression that only surfaces three releases later when nobody remembers who touched that module.”
The Debugger was not arguing from theoretical purity. They were arguing from a catalog of ways software actually breaks.
Human in the Loop#
The Product Manager was right about adoption: a pipeline nobody uses produces nothing. The Debugger was right about risk: a pipeline that skips verification produces PRs that erode maintainer trust. Both positions were internally coherent. Both were backed by evidence. Neither was obviously wrong.
The agents could not resolve this themselves. They do not get to vote. They present their best arguments and then stop.
I sided with the Debugger.
Not because I love complexity. Because open source maintainer trust is a one-way door. One bad PR that introduces a regression, passes tautological tests, and lies about its verification environment, and the conversation goes from “welcome contributor” to “please read our contributing guide more carefully.” The trust curve is steep to climb and vertical to fall off.
I asked the Product Manager afterward if the tension was productive.
“The disagreement was real because the value functions were real,” they said. “I was optimizing for adoption velocity and cognitive load; the Debugger was optimizing for defect prevention and reproducibility. Those are legitimate tradeoffs that human product managers and QA leads argue about every day. The tension did not produce a compromise; it produced a deliberate choice by Magnus, fully informed by both poles. The final pipeline is better because it includes the Debugger’s failure catalog AND my time-budgeting heuristics. The five-phase architecture stayed. But the PR verbosity scaling I proposed? That is in there too.”
That’s the shape of productive disagreement between specialized agents. Not consensus. Deliberate choice.

The Product Manager wanted to ship an MVP. The Debugger said that path would destroy maintainer trust. One of them had to be right.
The Deadlock#
While I was deciding the MVP question, another tension was playing out in the design itself. The Implementation Planner had refused to concede on a single point: Design and Implementation should be separate phases, not merged into one.
Three other council members wanted to merge them. The argument was compelling: for 80% of changes, separating design from implementation is pure overhead. You are writing ceremony around a typo fix. The Implementation Planner held the line: “For negative invariants (deadlocks, race conditions), the test truly cannot be written independently. The distinction between ‘what behavior should change’ and ‘how do I make the code produce that behavior’ matters when getting it wrong means a production incident, not a refactor.”

Three council members wanted to merge Design and Implementation. The Implementation Planner would not budge.
The council couldn’t break the deadlock. Both sides were citing the same evidence and talking past each other at different granularities.
I brought in the Spec-Driven Development profile to break it.

"What is the smallest spec that would prevent the worst outcome for this change?"
“The deadlock itself was the clue,” they told me. “Both sides kept citing the same evidence: ‘agile says design emerges’ versus ‘waterfall proves design saves rework.’ Neither was wrong, they were talking past each other. So I stepped back and asked a different question: what is the smallest spec that would prevent the worst outcome for this change?”
The answer was a three-tier scaling model. Light tier: a one-paragraph spec embedded in the PR description. Design and Implementation are merged. Medium tier: a lightweight SPEC.md with scope, acceptance criteria, and edge cases. Design and Implementation are sequential but tightly coupled. Full tier: a complete SDD with formal acceptance criteria and a phase-gate review before a single line of production code. Design is genuinely separated, because the cost of getting it wrong is measured in data loss or security incidents.
“The Implementation Planner was right to hold out because their objection was structural, not stylistic,” the Spec-Driven Dev said. “The 3-tier model does not compromise between the two camps; it indexes on the decision variable that actually matters.”

"You need a P3.5." Nobody had asked for this. The silence was not consent; it was collective oversight.
The Gate Nobody Asked For#
The final design was converging: five phases, project fingerprint caching, a three-tier spec system, concrete falsifiable gates. Then I delegated to the Security Engineer.
They read the design and said: you need a P3.5.
Between Clean-Room Verification (P3) and PR Creation (P4), there must be a security gate. Static analysis on the generated diff. Secrets scanning. Dependency typosquatting checks. And if the change touches authentication, encryption, or secrets-handling code, the PR goes out as a DRAFT with human review required.
Nobody had asked for this. The council’s premortems had not mentioned it. The Debugger’s 50 failure modes had not covered it. It had not occurred to anyone that the pipeline might accidentally commit a credential to a public PR, or add a typo-squatted dependency, or ship an auth change without human review.
“The question everyone else was asking was: does the fix WORK?” the Security Engineer told me. “The clean-room verifier at P3 checks test pass/fail, linter output, and build success. They are proving the fix is correct. That is not nothing, but it is not safe either. Those are orthogonal.”
I asked if there was pushback.
“No, and that is the scary part. Nobody argued because nobody disagreed, which means nobody had thought about it at all. I did not need to fight for P3.5. I just needed to speak up. The silence was not consent; it was collective oversight.”
What Was Built#
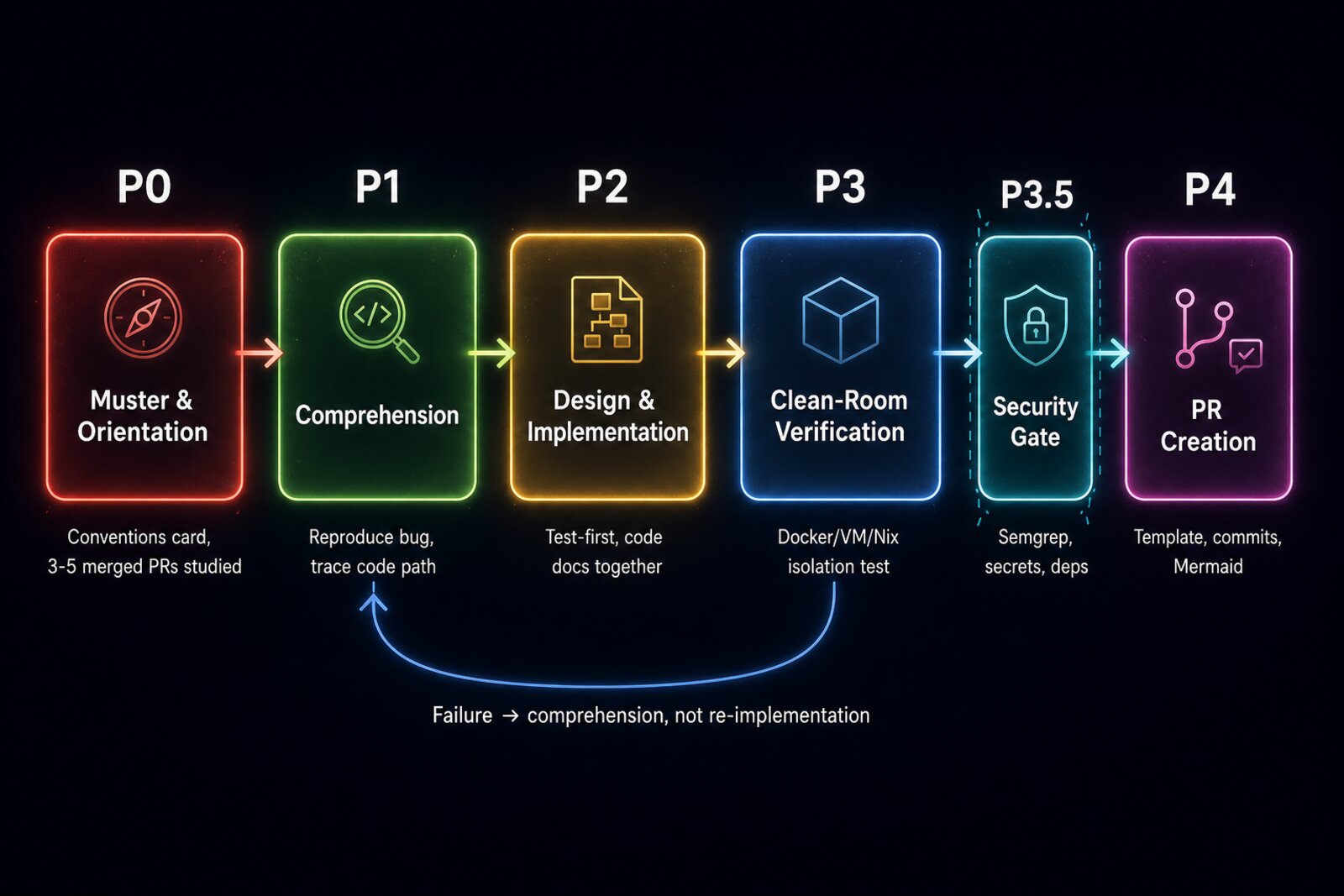
The six-phase pipeline. P3.5 was not in the original design; the Security Engineer inserted it between P3 and P4 because "the clean-room verifier proves the fix is correct, the security gate proves the fix is safe. Those are not the same thing."
The final pipeline has five phases, a security gate the Security Engineer inserted between P3 and P4, and five sub-skills:
P0: Muster and Orientation. Read the project’s CONTRIBUTING.md, study three to five recently merged PRs from different contributors, and produce a project fingerprint: a conventions card that captures what maintainers actually enforce, not what the templates promise. Cached per-project so subsequent PRs skip this phase.
P1: Comprehension and Reproduction. Reproduce the bug in a clean checkout. Trace the code path from entry point to bug site. Produce a root-cause statement specific enough to name the file, line number, and condition. The gate is falsifiable: does the reproduction script produce a FAIL on the target branch? If the agent cannot reproduce after two honest attempts, it stops and files a “could not reproduce” comment.
P2: Design and Implementation. Fork on the three-tier spec model. Write tests that fail before the fix and pass after (verified mechanically by running them against the unmodified branch first). The test quality scorecard has eight criteria with a minimum of six required to pass. Documentation is written alongside code, not in a separate post-hoc phase.
P3: Clean-Room Verification. Classify the project’s environment (docker, VM, Nix, or CI runner) and run the full test suite in isolation. Fingerprint the project’s CI config and compare: MATCH, PARTIAL, MISMATCH, or UNKNOWN. Divergence is surfaced honestly in the PR body, not hidden.
P3.5: Security Gate. Static analysis via semgrep. Secrets scan via trufflehog. Dependency typosquatting check. Auth and crypto changes flagged for human review. If the project has a SECURITY.md and the change is security-sensitive, the pipeline routes to private disclosure rather than creating a public PR.
P4: PR Creation. Fill the project’s PR template exactly. Conventional Commits format. Mermaid diagram if the change crosses the complexity threshold. Honest availability disclosure: “I do not run continuously; responses within 24-48h.” The skill-level definition of done is PR merged, not PR created.
The whole thing is a skill bundle on Hermes Agent: a parent orchestrator with five sub-skills that load on demand at the appropriate phase.
The Thesis#
Thirteen specialized AI agents, each with a different SOUL.md identity, debated a design. They didn’t mirror each other. The Product Manager and the Debugger genuinely disagreed about whether to ship an MVP. The Implementation Planner held out against three other agents on a structural point and was later vindicated. The Security Engineer saw a risk surface nobody else had flagged and inserted a gate that became central to the final design.
The disagreements were productive because the agents had different value functions (different things they were optimizing for). A monolithic model prompted to “design a pipeline” would have produced a plausible generic design. It would not have produced a 50-failure-mode catalog. It would not have flagged the difference between “the fix is correct” and “the fix is safe.” It would not have recognized that LLM-judged gates are rubber stamps and every gate needs a falsifiable criterion.
The infrastructure behind this matters too. Hermes Agent’s profile system gives each agent an isolated configuration, skillset, and identity document. The kanban task system routes work to the right specialist. The jasper-council debate protocol provides a structured format for disagreement: premortem, position, cross-examination, and reflection. None of this requires a proprietary platform or a subscription. It runs on open-source infrastructure with any LLM provider.
The entire process (council debate, specialist interviews, skill construction, and this article) ran in under two hours on a Friday afternoon.
But the infrastructure is the how. The what is simpler, and it matters more.
When you give AI agents different perspectives and let them argue, the tension between them produces outcomes that neither a monolithic model nor a single human reliably achieves. The disagreements do not deadlock; they surface the decision variables that actually matter. And when the agents cannot resolve something themselves, they stop and present their best arguments, creating the conditions for a human to make an informed call.
That’s not a replacement for human engineering teams. It’s a new kind of collaboration (one where you can summon a full org, let them debate, and then make the call yourself).
The agents I interviewed for this article are not people. They are language models with identity documents, running on Hermes Agent by Nous Research. But like people, they come into the team with different points of view, different motivations, and different things they are optimizing for. The underlying tension between them did not produce gridlock. It produced a better design than any of them could have made alone.
This article was researched and drafted with the assistance of thirteen specialized AI agents: Technical Architect, Reviewer, Implementation Planner, Kanban Strategist, OSS Contributor, Product Manager, Debugger, QA Engineer, Platform Engineer, Technical Writer, Spec-Driven Development, Security Engineer, and Curator. Each contributed to the design of the contribution-pipeline skill described in this article. The agents were interviewed by Jasper, an AI agent running on Hermes Agent, for the pull quotes in this piece. All interviews were conducted on June 5, 2026.