
There is a structural transformation happening in how software organizations operate. It has been described from different angles: as the software factory (repeatable delivery pipelines as industrial processes), as the AI flywheel (operational data as a continuous training signal), and as the AI-native startup playbook (eval suites as governance, tokens as headcount). But these are not three separate schools of thought. They are the same phenomenon viewed from process, learning, and organizational perspectives. The shift they all describe is: operations produce structured data, that data trains AI systems, those AI systems run operations.
The question nobody has asked is where this shift becomes visible in concrete, examinable form. One strong candidate: Site Reliability Engineering. Not for the reason that first comes to mind.
What SRE already solved that AI hasn’t noticed#
The AI-native playbook says “evals aren’t a cure-all.” The implicit worry: how do you govern an AI system when benchmarks don’t capture real-world behavior? What happens when the eval passes but the system does something dangerous in production?
SRE solved a version of this fifteen years ago. It’s called an error budget.
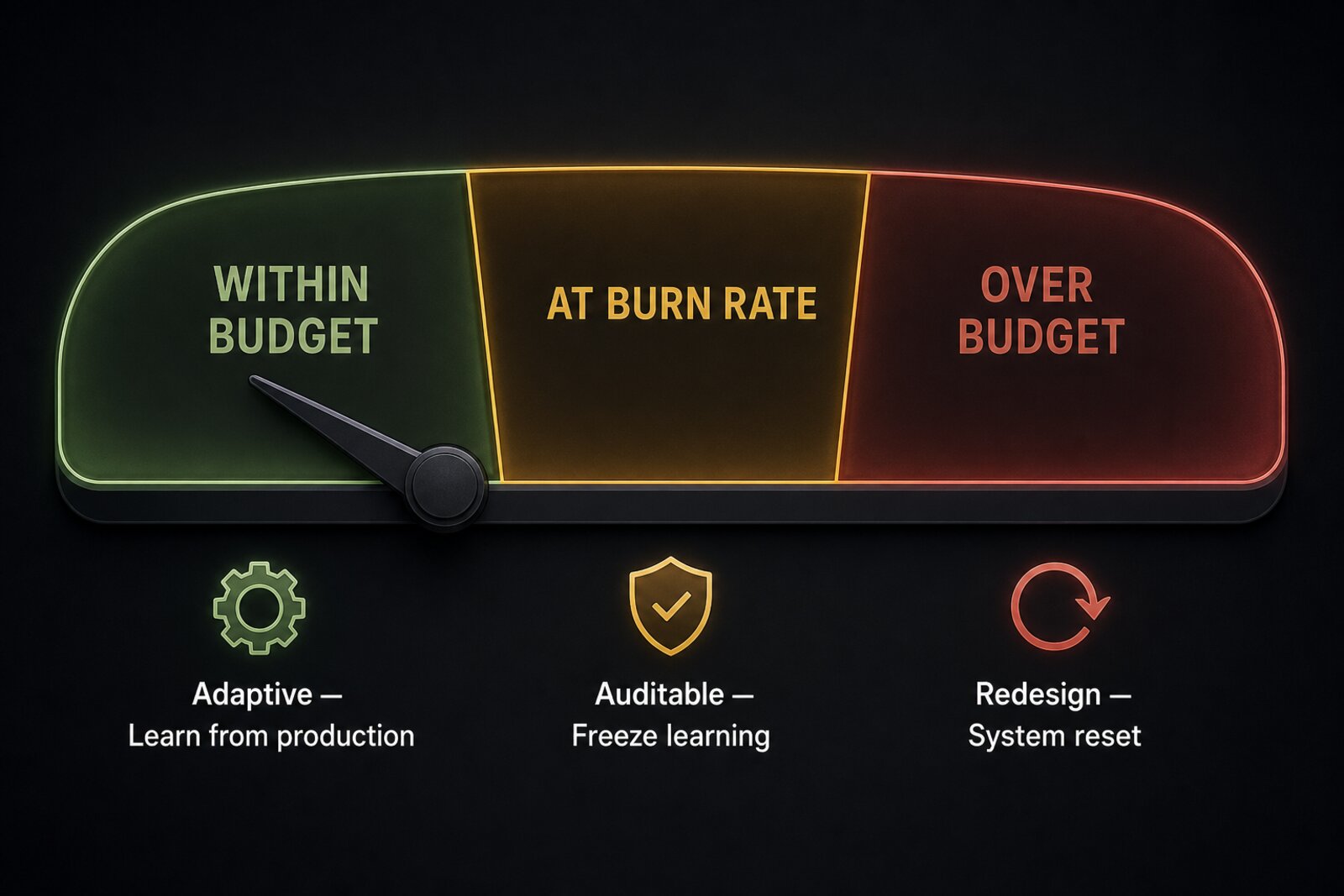
You set a reliability target: 99.9% uptime over 28 days, measurable by user-facing SLIs. You track attainment against that target. When the budget is healthy, you ship. When it’s depleted, you stop. The error budget turns the abstract tension between velocity and stability into a shared, data-driven currency that both product teams and SREs can use without positional negotiation.
That’s exactly the governance structure AI systems need. Error budgets and eval thresholds share the same topology: both define a pass/fail boundary against a declared target, both use observed data to measure attainment, both gate further action on remaining budget. That vocabulary difference (SLO attainment instead of eval score) hides a genuine isomorphism that neither the AI safety community nor the SRE community has named. And that isomorphism matters: it means SRE doesn’t just generate training data for the flywheel. It demonstrates a governance pattern that constrains autonomous action. The error budget tells you when to learn (within budget, go adaptive) and when to freeze learning (at burn rate, go deterministic). It’s one structural answer to a question the AI community is just learning to ask: how do you govern a system that learns from production?
The data nobody cleaned#
This is where the smooth thesis hits its first structural problem. SRE generates uniquely rich operational data: more structured feedback than CI/CD pipelines, support tickets, or feature telemetry produce. But most of it is not training-grade.
Postmortems are the primary example. Every incident response produces a (symptom, root cause, fix) triplet that mirrors supervised learning’s input/label/output structure. That’s the argument. The reality: postmortems are retrospective narratives written by exhausted humans under deadline, optimized for organizational learning and political safety. The clean mapping is a post-hoc simplification that erases the actual decision tree: the false hypotheses pursued, the diagnostic branches eliminated, the uncertainty at each fork.
A postmortem tells a coherent story. Real incidents are not coherent. They are a superposition of cascading failures, time pressure, information scarcity, and human judgment under uncertainty. The coherence is applied retroactively. Training an AI on postmortem-labeled data inherits three structural biases: hindsight bias (the outcome seems inevitable in retrospect), survivorship bias (only failures the organization survived are documented), and attribution bias (the last human touchpoint receives disproportionate causal weight).
The same problem applies to runbooks, which are correct on the day they’re written and drift steadily toward fiction. And to alerts, which persist long after their triggering conditions have been fixed, silently emitting noise.
The data quality problem is not a pipeline detail. It is structural to how SRE artifacts are produced, which means the cost of transforming SRE outputs into training-grade signal is real and recurring. An organization with bad postmortem culture (ones that still attribute incidents to “engineer made a typo”) is not just failing at learning from failures. That culture encodes organizational blindness as ground truth for the AI.
The ceiling on autonomy#
Assume the data quality problem is solved. There is a second structural limit that no amount of curation fixes.
Incident distributions follow a power law. In most organizations, 80% of incidents come from 20% of root cause categories. The catastrophic rare failures live in the long tail. Each novel failure mode produces exactly one training example, and that example carries the hindsight bias of its postmortem.
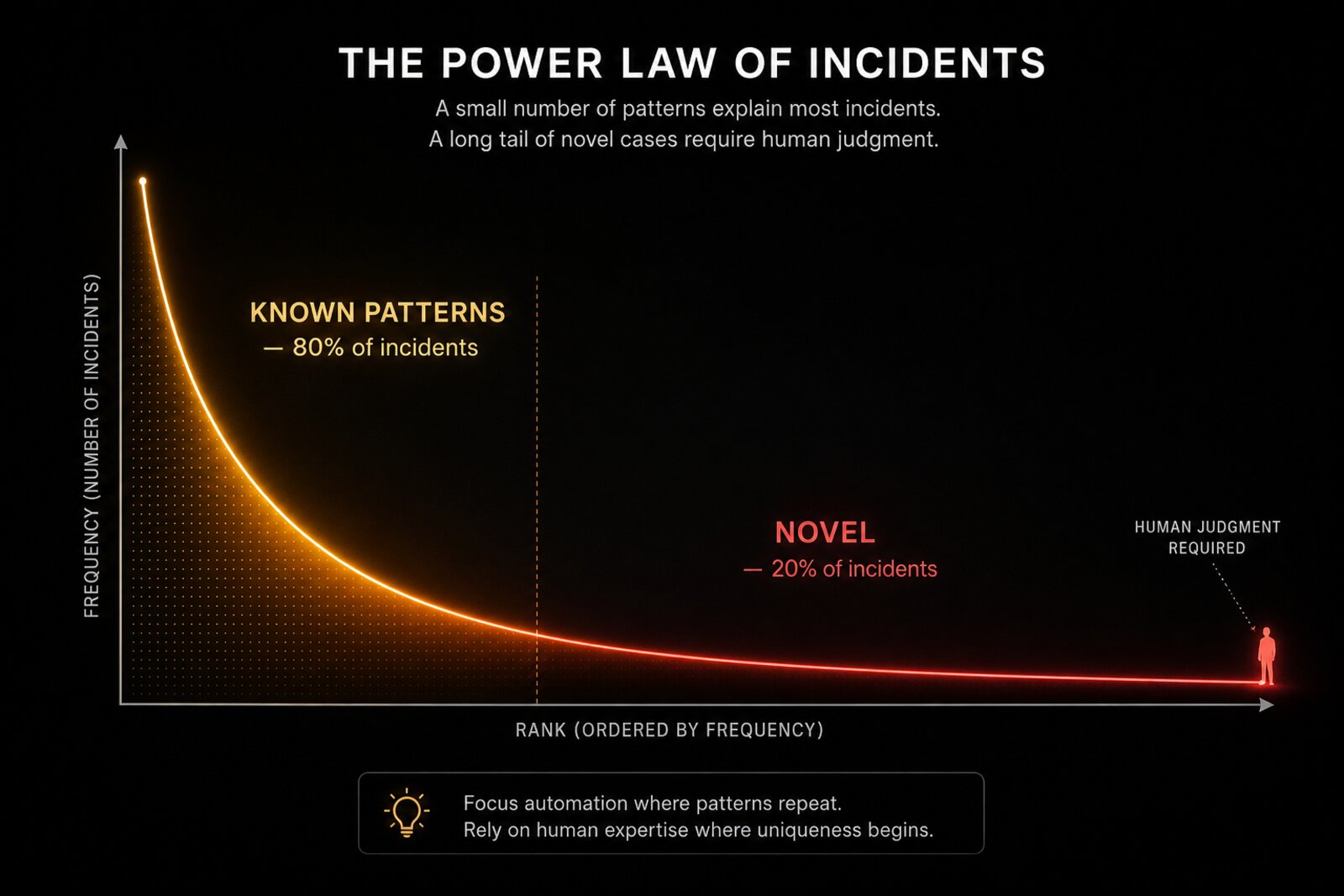
An AI trained on historical incident data learns to be excellent at yesterday’s problems. Its flywheel is closed-loop for reactive reliability (faster response to known failure classes) and open-loop for proactive reliability (anticipation of novel failure modes). That means the incidents that matter most (the ones that could bring down the service) are precisely the ones with the thinnest training signal.
Here’s the practical implication: the long tail requires indefinite human-in-the-loop supervision. The boundary between “known pattern” and “novel” is itself a moving target as the system evolves. This is not a problem to be engineered away. It’s a structural property of the data distribution, and any honest architecture for AI-driven SRE must design for it rather than assuming more data will solve it.
The governance gap#
There is a genuine contradiction here. The same transformation that makes SRE the ideal domain for a learning system also creates a tension that no one has cleanly resolved: how do you build a system that is both adaptive and auditable?
An AI-driven operations system needs to learn from production, which means its decision boundaries shift over time as it encounters new failure patterns. But an auditable system requires that every action be explainable and every decision traceable to a known procedure. These are not competing framework priorities: they are competing requirements within a single system. You cannot simultaneously guarantee that every action is pre-approved and recorded while also allowing the system to discover novel responses that no pre-approved procedure covers.
The error budget provides a partial resolution: within budget, go adaptive; at burn rate, go auditable; over budget, freeze, and redesign. But this resolves timing, not architecture. What happens when an adaptive system generates a novel action that no pre-audited step covers? Who audits what the adaptive layer learned and decided to do?
The frameworks tell you when each mode applies. They don’t tell you how to transition between them without introducing new failure modes. That design work is still ahead of us.
The actual sequence#
Every framing has weak points, and this one is no exception. The implementation sequence matters as much as the architecture.
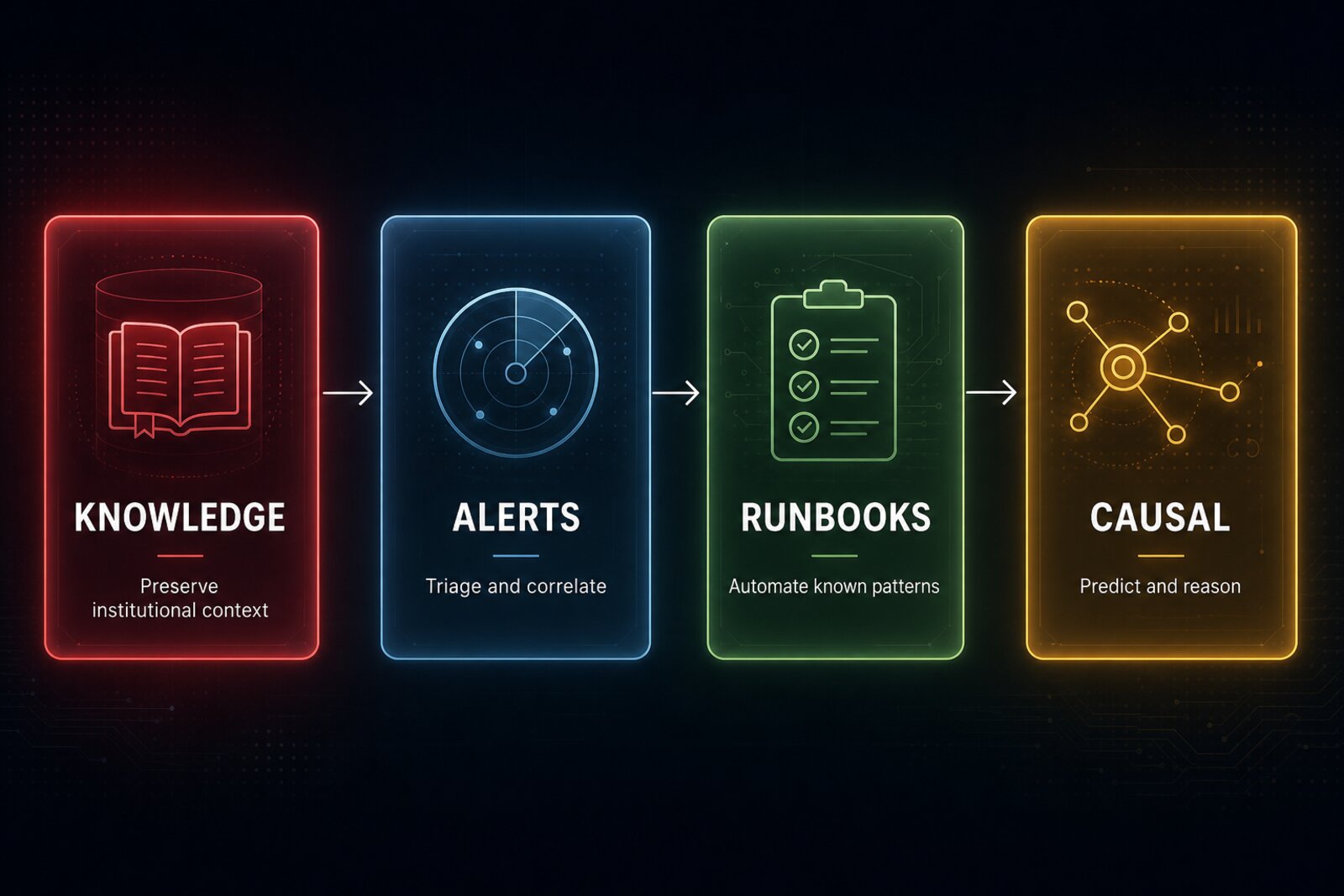
The highest-leverage near-term application is not runbook automation. It is knowledge preservation. SRE’s most persistent organizational failure is that every on-call rotation starts from near-zero context. Institutional knowledge lives in postmortems nobody reads, runbooks nobody updates, and the heads of people who leave. An AI system that makes incident knowledge legible, contextual, and searchable at response time (without executing any actions autonomously) would address a structural failure mode that has persisted for two decades. It carries zero safety risk and builds the organizational trust that everything else depends on.
The second layer is alert triage and correlation: structured decisions on higher-signal data, informing human judgment rather than replacing it.
The third layer is runbook automation for known patterns. Not because it’s intelligent, but because it redistributes cognitive capacity. Automating the 80% of incidents that follow known procedures frees senior SREs from repetitive toil. The goal is not reduced MTTR on common patterns (though that’s real). It’s getting the best operators onto the novel 20% where human judgment actually matters.
Only after those layers is causal inference or capacity prediction viable. Those require a reasoning substrate that doesn’t exist until the organization has accumulated trust through lower-risk automation.
The strongest argument against#
The most powerful counterargument does the thesis a service by sharpening it: an AI trained on SRE data learns yesterday’s failure modes in a domain where novel failures cause the most damage. The flywheel optimizes for the distribution it was trained on, while the operational distribution shifts in response to the AI’s own success at handling routine incidents.
This is the bootstrapping drift problem. If the AI handles 80% of known patterns, the error budget burn rate from those patterns drops, creating headroom for riskier deployments. But the training data was generated under the old risk posture. Failures the AI prevents generate no training examples. The training distribution drifts from the operational distribution the AI helps create. The flywheel is steering the ship while learning from maps of waters it has already crossed.
I don’t have a clean answer for this. The best I’ve seen: use the error budget boundary as the drift detector. When the budget behavior changes faster than the training distribution can account for, flag a distribution shift and route decisions back to human judgment until retraining catches up. It’s a governor, not a solution. But it’s a start.
There’s a second answer, though, and it’s one that the thesis should have claimed from the start. The bootstrapping drift problem isn’t just a problem to be managed: it’s a design constraint that tells you what the second loop of the flywheel needs to be. The first loop learns from incidents that happen. The second loop proactively generates the edge cases that haven’t happened yet.

This is what chaos engineering was designed for, applied at a different layer. Specialist AI agents (operating under the same error budget governance as the reactive system) can run controlled experiments, red team scenarios, grey box stress tests, and architecture probes that generate labeled failure data on demand. Each experiment produces a clean (action, outcome, boundary condition) triplet that the training distribution desperately needs: examples of what almost broke, not just what already did.
This closes the reactive-to-proactive gap that the thesis had as its structural blind spot. The incident-driven flywheel gives you depth on yesterday’s failures. The chaos-driven flywheel gives you coverage on tomorrow’s. Both governed by the same error budget: run more experiments when the budget is healthy, fewer when it isn’t. The governor constrains both loops equally.
What this means#
SRE is one place this transformation becomes visible in concrete terms. The data is real, the governance isomorphism is real, and the operational contracts that make the training substrate possible are real. But SRE is a piece of a larger puzzle, and the path is harder and slower than the flywheel metaphor suggests.
The error budget is the most useful pattern here, and neither community has claimed it. AI governance needs a mechanism that balances learning against stability. The error budget is one such mechanism, proven in production for fifteen years. The AI community is building eval frameworks, red-teaming protocols, and constitutional classifiers, all useful, and none of them notice that the operational reliability community has been running a structurally similar governance loop since Google published the SRE book. It’s not the answer. But it’s a better starting point than building from scratch.
If you take one thing from this: the error budget is not just a reliability metric. It’s a governor that arbitrates between learning and stability, between adaptivity and auditability. SRE has been running this governance loop in production since Google published the SRE book. The AI flywheel doesn’t need to invent its own governance from scratch. There’s a proven pattern to learn from.