
Most companies are playing a game they don’t understand the rules to. They’re standing in a room full of competitors, all of them staring at the same two doors. One door says OpenAI. The other says Anthropic. They believe the strategic decision is which door to walk through. They believe this so deeply that they’re paying enormous premiums for inference that’s past the point of diminishing returns, and getting nothing their competitors aren’t also getting.
The real game isn’t behind either door. The real game is what you build after you walk through. And Google just published the rulebook.
The Diagram That Changes Everything#
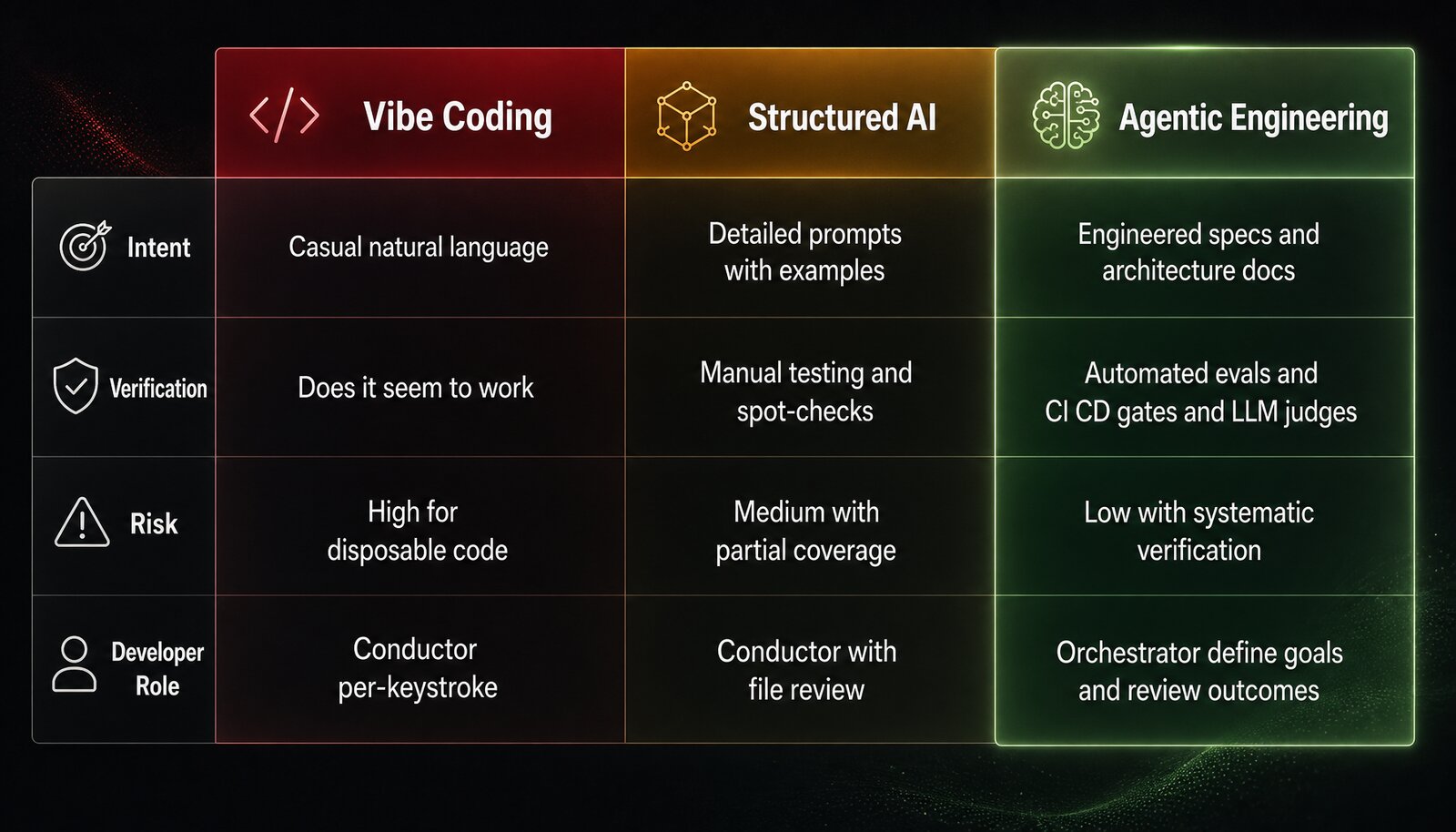
In May 2026, Google dropped a 51-page whitepaper called The New SDLC With Vibe Coding. Addy Osmani, Shubham Saboo, and Sokratis Kartakis laid out the full spectrum from casual AI-assisted coding to disciplined agentic engineering. The paper is full of useful frameworks: the six types of context, the conductor-to-orchestrator transition, the factory model. But there’s one visual that matters more than everything else.
It’s a diagram. A simple diagram. The model sits in the center. Around it, in concentric layers, sits the harness: instructions and rule files, MCP servers and tool definitions, guardrails and hooks, testing infrastructure and evals, observability and tracing, scaling and deployment. The diagram doesn’t label the proportions explicitly. But Cole Medin, who broke the paper down in a video analysis, read the visual and assigned the number: the model is 10% of the system. The harness is the other 90%.
This isn’t a number Google stamped on the page. It’s a reading of their visual. And it goes further than Anthropic’s own published guidance, which Medin notes says “the harness matters as much as the model.” Google’s framing, as Medin interprets it, is sharper: the harness matters more. Considerably more.
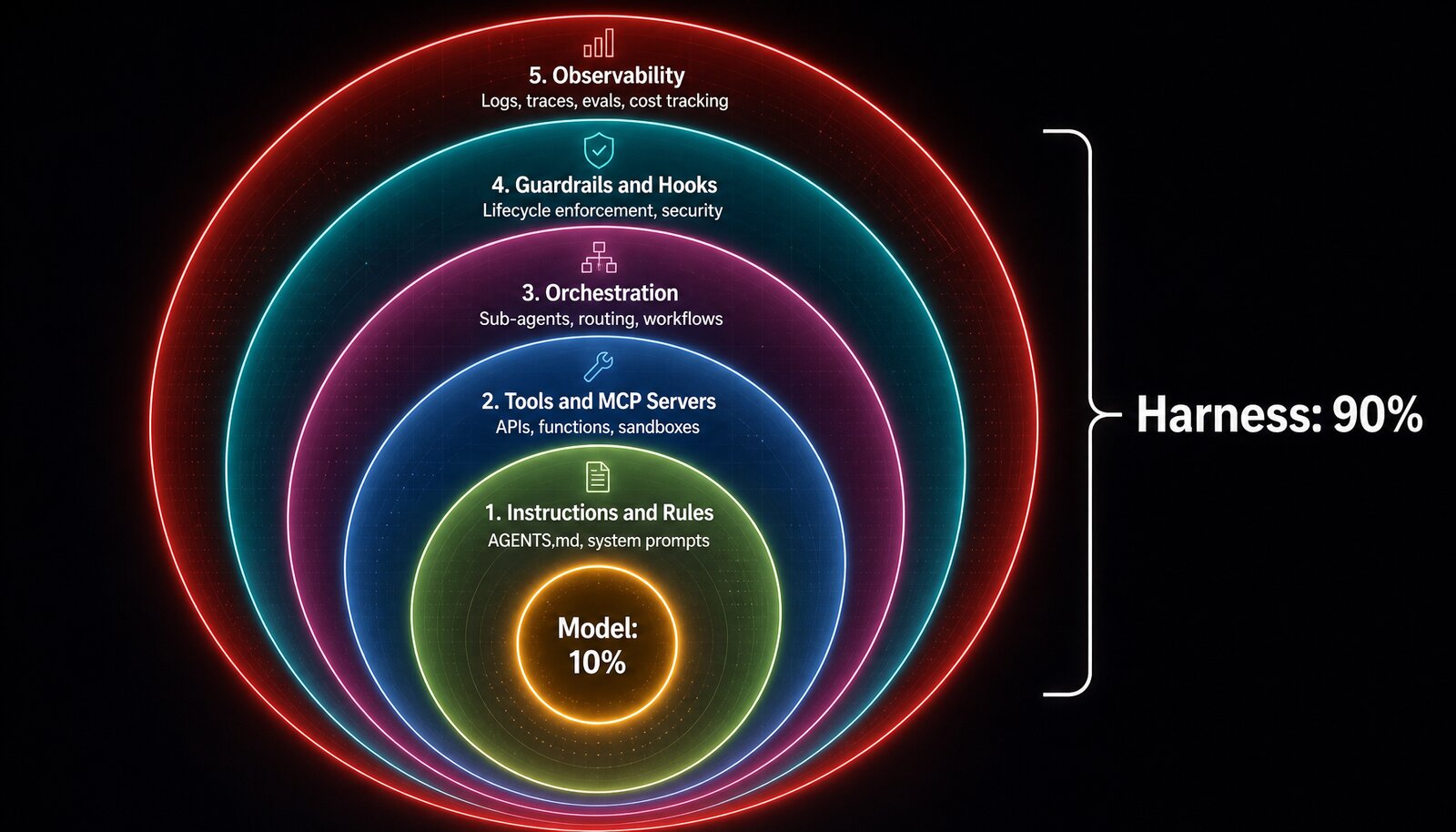
If this is true (and the evidence is substantial), then most companies are hyper-focusing on the wrong decisions in their AI strategy.
The Receipts#
The whitepaper backs this up with benchmark results. One team using Terminal Bench 2.0 moved a coding agent from outside the Top 30 to the Top 5 by changing only the harness. No model change. No model upgrade. Just better instructions, better tools, better guardrails.
LangChain did something similar: they raised a coding agent’s score by 13.7 points by tweaking only the system prompt, tools, and middleware. That’s roughly the gap between Claude Sonnet and Claude Opus on the same benchmark. You can make Sonnet perform at Opus level through harness engineering alone.
The practical implication is uncomfortable for anyone who’s been treating model selection as a strategic decision: you could switch from a frontier model to a cheaper open-weight model tomorrow and, with the right harness, see your output quality stay flat or even improve. The model isn’t carrying the weight you think it is.
The Economics Nobody Talks About#
The whitepaper frames this through capital expenditure versus operational expenditure, and it’s one of the cleanest arguments for harness investment I’ve seen.
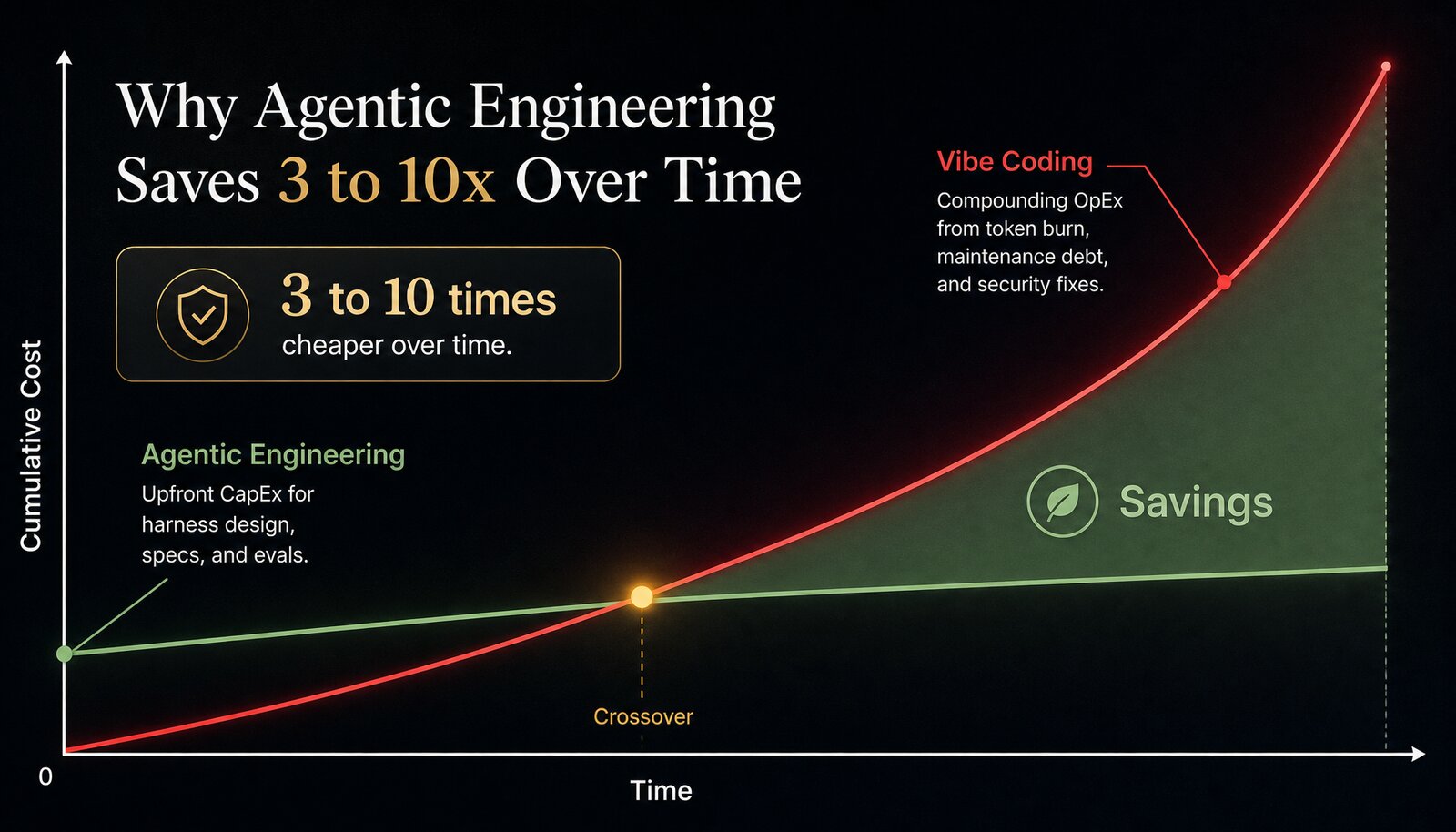
Vibe coding (throw prompts at a frontier model without structure) has near-zero CapEx. You pay your API subscription and you go. But the OpEx compounds: every unstructured prompt burns tokens. Every failed generation requires a fix cycle that burns more tokens. Every piece of vibe-coded code that ships without validation becomes maintenance debt that burns engineering time six months later. The security vulnerabilities that slip through because nobody wrote evals become production incidents that burn everything.
Agentic engineering flips the math. High CapEx upfront: you invest time and money in harness design, spec authoring, eval infrastructure, context engineering, guardrail configuration. But the OpEx drops dramatically because the harness eliminates the compounding waste. The agent operates within a governed system. First-pass success rates climb. Maintenance debt shrinks because code is generated against specs and verified against evals, not shipped on vibes.
Cole Medin summarizes Google’s position with a number: agentic engineering is three to ten times more reliable and cheaper than vibe coding. The crossover point (where the upfront harness investment pays for itself in reduced operational burn) arrives quickly. The only reason to stay on the vibe coding side of the curve is if you can’t afford the upfront investment. And if that’s true, you’ve got bigger problems than model selection.
Why Nobody Will Sell You the Answer#
Here’s the part that should make you uncomfortable. The companies best positioned to build and sell you a harness (Anthropic and OpenAI) have a structural disincentive to do so.
Their revenue depends on you believing the model is the product. That inference is where the value lives. That the strategic question is “Claude or GPT?” If they built and sold you a harness that made the model interchangeable, you’d discover what Google’s diagram already shows: the model is a commodity input. You’d start routing architecture questions to the expensive model and test generation to the cheap one. Your inference bill would drop. Their revenue would drop with it.
This isn’t a conspiracy theory. It’s the ordinary behavior of a company whose business model depends on a specific layer of the stack being perceived as the critical layer. The incumbents aren’t going to commoditize themselves. They’re going to keep telling you the model matters most, because that’s what they sell.
The harness is the moat. Now you have a choice to make, and it’s bigger than it looks.
You can buy a harness. Cursor, Copilot, Cody: these are real products that ship a working harness today. The pitch is clean: pay the subscription, get the tools, start building. The trap is that you’re not buying a tool. You’re making an architectural bet on a single vendor’s model selection, their pace of development, their roadmap priorities, and their pricing model, in perpetuity. Swapping harnesses is not like swapping SaaS vendors. The harness becomes the substrate your engineering organization operates on. Your specs live in its format. Your evals run against its verification layer. Your engineers internalize its workflow. The switching cost compounds with every month of operation. This is a generational investment decision dressed in a monthly subscription.
Or you can build. Assemble from open-source components, invest in your own specs and evals and guardrails. Higher upfront cost, higher control, and the asset you create is yours. It compounds. Every spec you write makes every future agent run better. Every eval you design catches failures before they ship. The harness becomes an engineered resource that lives in version control, improves with every production incident, and can’t be replicated by a competitor who subscribes to the same SaaS platform you do.
What a Harness Actually Looks Like#
The harness is not just better prompts or a well-configured IDE. The harness that matters (the one that separates a vibe coder from a solo software factory) has real architectural bones.
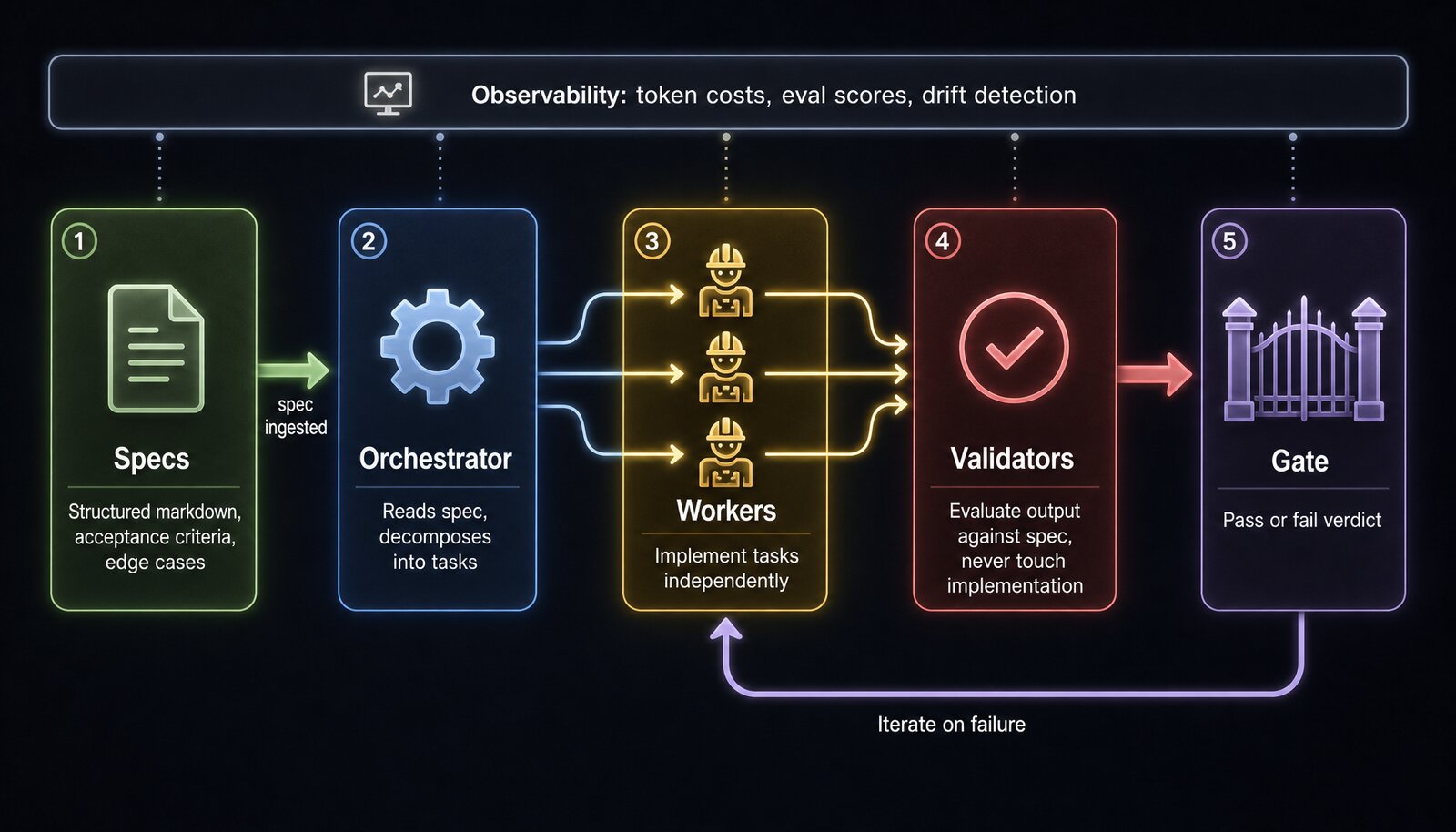
A specification layer where humans write intent, not code. Specs are the primary artifact. Structured markdown documents containing acceptance criteria, behavioral expectations, constraints, and edge cases. The spec is not a suggestion. It is the contract. The agent implements against it, and every deviation is a failure caught by the verification layer.
Role-separated agents that cannot judge their own work. An orchestrator reads the spec and decomposes it into tasks. Workers implement those tasks. Validators independently evaluate the output against the spec, and the validator never touches the implementation. This separation of concerns prevents the single biggest source of AI coding failure: the agent that wrote the code also deciding whether the code is correct.
Evals that verify the trajectory, not just the output. Tests check deterministic behavior: given this input, does the function return that output? Evals check non-deterministic behavior: did the agent choose the right tools, follow the correct reasoning path, and produce output that meets the quality bar? Both are mandatory. Without trajectory evals, you cannot detect the coding agent that took a creative but catastrophically wrong path and produced output that happens to pass the unit tests.
Guardrails that fire deterministically. Hooks at specific lifecycle points (before a tool call, after a file edit, before a commit) that enforce rules the agent should never forget but often does. No hardcoded credentials in generated code. No API calls to unapproved endpoints. No commits that skip the eval gate. These are not prompts. They are code.
Observability that tracks what matters. Token costs per spec, per feature, per deployment. Eval scores over time: are your agents getting better or drifting? Drift detection: when does the same spec start producing worse output, and why? This is the instrumentation layer that tells you whether your harness is improving or degrading.
And then the whole thing compounds. Every spec you write makes every future spec more informed. Every eval you add catches that class of failure forever. Every guardrail you harden prevents a regression permanently. The harness is an engineered resource that lives in version control and gets better with every production incident. It is the only part of the AI stack where investment actually compounds.
The open-source primitives for all of this are already here and running in production. The pattern they enable is the same pattern that made Linux unstoppable in the 1990s: a shared infrastructure layer that nobody owns, nobody charges rent on, and everybody improves. The companies that adopt this stack are building their own harness from commoditized components and investing their engineering time in the parts that actually differentiate: their specs, their evals, their domain-specific guardrails, their integration surface.
The vendors who sell you a bundled harness-plus-model are selling you the thing that should be your competitive advantage. And they are charging you rent on it.
What You Can Build With Today#
The open source pieces are not hypothetical. They exist, they are actively maintained, and they are individually strong. The gap is not in any single component. The gap is that nobody has wired them together into a single platform. And that integration work (the wiring between specs and evals, between guardrails and hooks, between observability and spec traceability) is the moat.
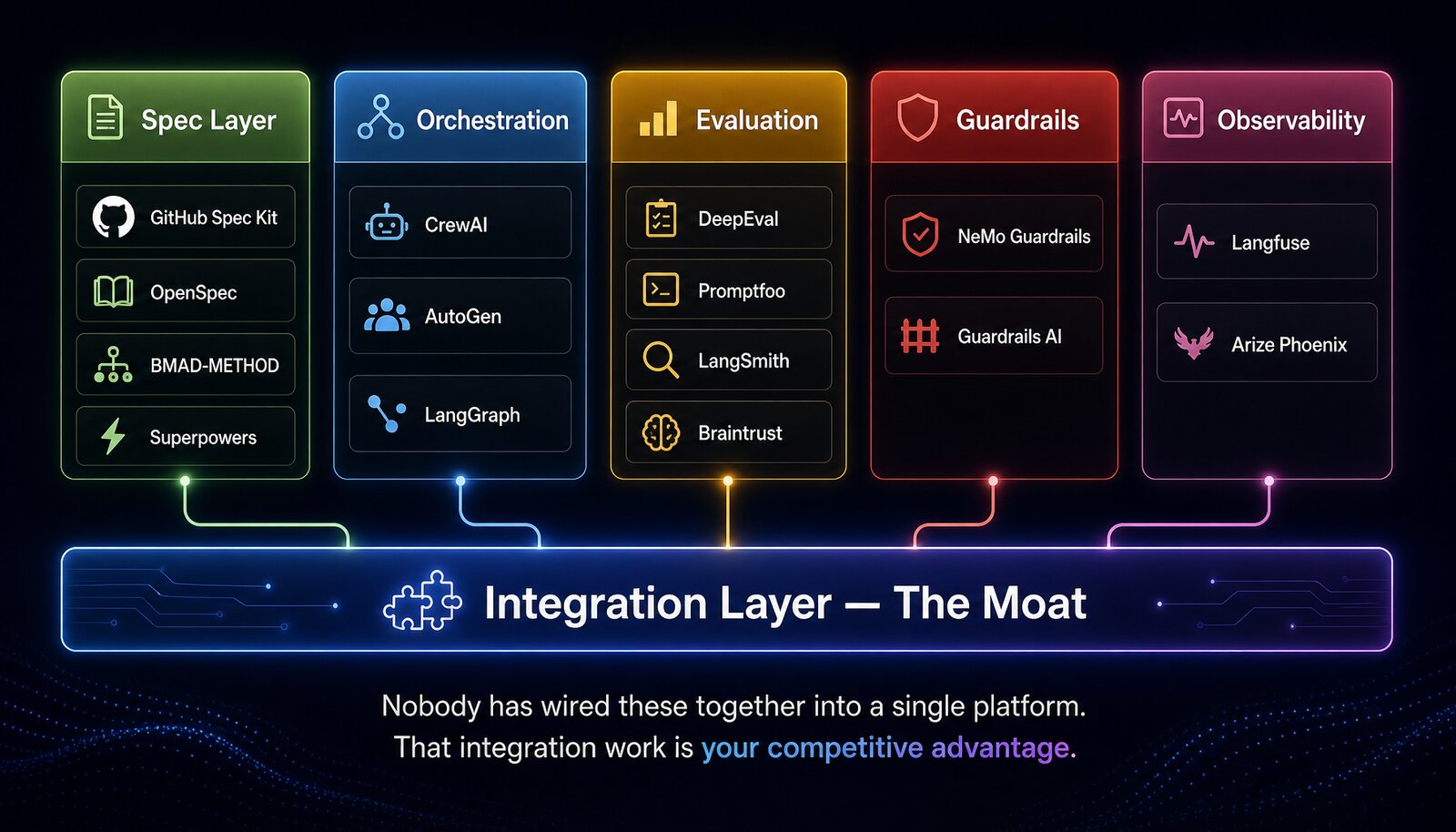
Spec-driven development. GitHub Spec Kit gives you a CLI that turns specs into plans into tasks. OpenSpec adds a three-phase state machine for brownfield changes. BMAD-METHOD ships 21 role-based agents across the full SDLC. Superpowers provides a skills framework with subagent test-driven development. These tools treat specs as the primary artifact. None of them connect a spec to an automated eval suite that verifies the agent actually satisfied what the spec asked for.
Multi-agent orchestration. CrewAI gives you role-based crews with a hierarchical manager that delegates and reviews: the closest thing to orchestrator/worker separation in open source. AutoGen and LangGraph provide graph-based and conversation-driven multi-agent patterns. But here is what none of them enforce: the validator must never touch the implementation. That separation is still a discipline you impose, not a constraint the framework guarantees.
Evaluation. DeepEval and Promptfoo give you frameworks for testing LLM output quality, red-teaming, and vulnerability scanning. LangSmith and Braintrust provide hosted eval platforms with LLM-as-judge capabilities. The missing piece: accepting a structured spec and auto-generating a scenario suite that computes per-requirement satisfaction scores. The spec-to-eval bridge (the thing that tells you whether the agent actually built what you asked for) is unbuilt in open source.
Guardrails. NVIDIA NeMo Guardrails and Guardrails AI provide programmable safety rails for conversational AI. These are not coding harness guardrails. There is no open source framework for pre-commit hooks that block hardcoded credentials, no API call allowlist enforced at the tool level, no eval gate that rejects a pull request below a quality threshold. The guardrail layer for agentic coding is empty.
Observability. Langfuse gives you self-hosted tracing with token cost tracking and latency visibility. Arize Phoenix provides drift detection and RAG evaluation. Here is what neither tracks: spec compliance over time. The measurement that tells you when a spec that used to produce good output has started producing bad output, and why.
The components are here. They are open source. They are individually capable. If you wanted to build a Software Factory harness today, you could. It would take integration work. That integration work (the wiring between these layers, the spec-to-eval pipeline, the guardrails that understand your architecture, the observability that tracks spec compliance) is your competitive advantage. It is the thing a competitor cannot replicate by subscribing to the same SaaS platform. It compounds with every spec you write, every eval you add, every guardrail you harden.
The Model Will Get Cheaper#
Every company eventually faces this choice. Do you buy a managed AI coding platform that bundles the model, the tools, the harness into one subscription? The pitch is compelling: turn it on, start coding, don’t think about infrastructure.
The trade is that you’re renting your competitive advantage from someone who also rents it to your competitors. Every company on the same platform has the same harness quality. The same guardrail sophistication. The same context engineering. The platform commoditizes its own customers.
Building your own harness (assembling it from open-source components, investing in your own specs and evals and guardrails) has higher upfront cost. But the asset you create is yours. And unlike the model, which gets cheaper and faster and commoditized by the month, the harness gets more valuable. It gets more specific to your codebase, your architecture, your customers. It’s the only part of the AI stack where investment actually compounds.
I wrote about this compounding dynamic in more detail in “What Replaces Money”. The same flywheel that replaces venture capital in a nano-unicorn is the same flywheel that makes a harness worth building. Every eval you write, every spec you formalize, every guardrail you harden: these are compounding assets. The model is a consumable.
That’s the game. Most companies are standing in front of two doors, asking each other which one is better, while the companies that understand the rules are behind the building, constructing the thing that actually matters.
You don’t need to pick between OpenAI and Anthropic. You need to pick between renting your competitive advantage and building it. The model isn’t the moat. The harness is.