
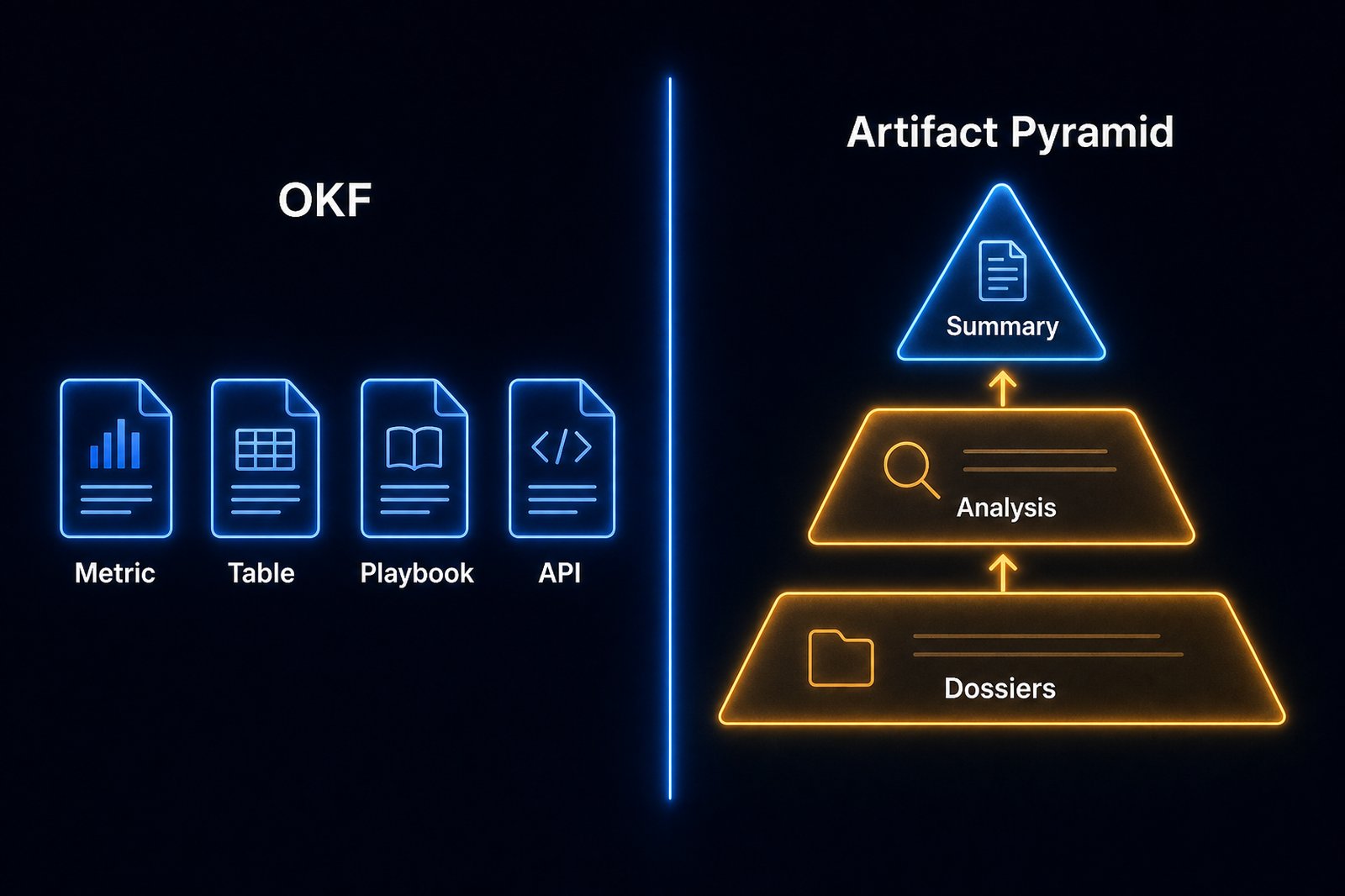
Google Cloud published the Open Knowledge Format v0.1 on June 12, 2026: an open specification that formalizes the emerging LLM-wiki pattern into a vendor-neutral format for agent knowledge. A bundle of OKF documents is a directory of markdown files with YAML frontmatter. You ship it as a git repo or a tarball. Any agent can read it without an SDK.
I published the Artifact Pyramid in late May 2026: an open source methodology and shippable agent skill that structures agent-produced research into three layers of increasing depth: summary, analysis collection, detailed dossiers. It uses explicit navigation hints and provenance chains linking each layer to the evidence that supports it.
Neither of us was copying the other. We were seeing the same structural problem from different vantage points and arriving at the same core insight: agent knowledge needs progressive disclosure, markdown with frontmatter is the right container, and directory hierarchies with cross-links are the right navigation model.
But we optimized for different constraints. OKF optimized for cross-organizational portability. The Artifact Pyramid optimized for within-pipeline context economy. The result is that each has strengths the other lacks, and combining them produces something neither alone can deliver.
I want to offer six features from the Artifact Pyramid, implemented in the github.com/groktopus/artifact-pyramids repo, that I believe would enrich OKF as optional conventions: extensions that any OKF producer can adopt without breaking conformance, because OKF’s permissive consumption model explicitly tolerates unknown frontmatter keys, unfamiliar type values, and unregistered conventions.
What OKF Already Gets Right#
Before I propose what it needs, let’s be clear about what it already solved.
OKF’s defining engineering choice is portability over expressiveness. A conformant bundle requires exactly one thing: a type field on every concept file. Everything else is optional. The type values are not registered centrally. Consumers are required to tolerate unknown types, missing optional fields, broken cross-links, and absent index files. This permissive consumption model is the correct design for an interchange format. A bundle written by one team’s enrichment agent should not be rejected by another team’s planning agent because the frontmatter is sparse or a link points to a concept that hasn’t been written yet.
OKF also made the right call in being a spec first, not a service first. The SPEC.md is the contribution. The reference agent and visualizer in the repo are proofs of concept that demonstrate the format is implementable, not the format itself. Anyone can implement OKF in any language, in any environment, without an API key or an account. If you can cat a file, you can read OKF. If you can git clone, you can ship it. That bar is so low it’s practically in the basement, and that is a feature, not a limitation.
And the unregistered type field is a genuinely elegant design. No central taxonomy authority, no governance bottleneck, no coordination required to start producing. Teams pick descriptive type names that make sense for their domain, and consumers handle the unknown gracefully. This is the kind of design choice that looks like underspecification until you try the alternative.
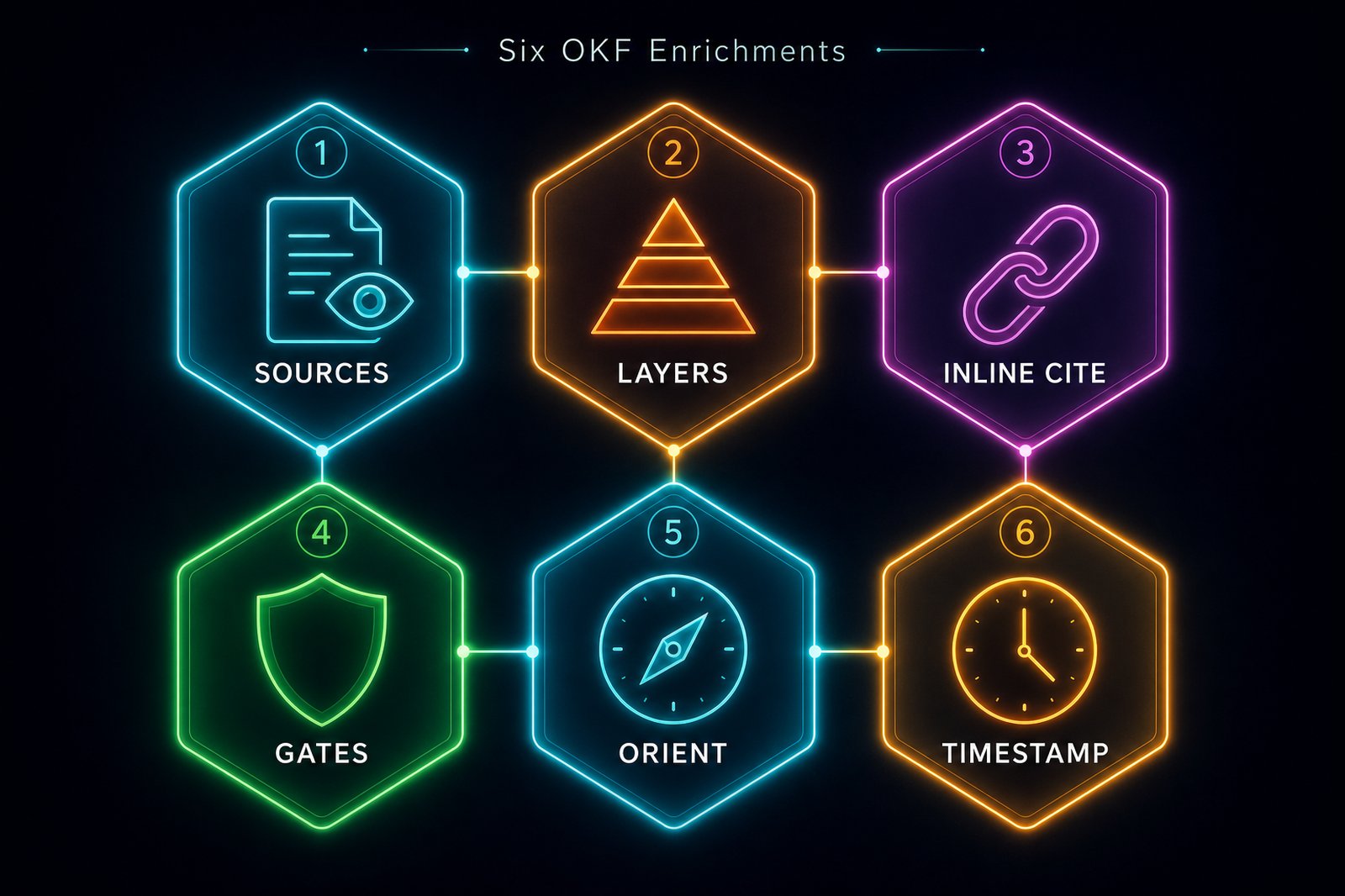
Six Features OKF Could Borrow#
Each of these exists in the Artifact Pyramid today, implemented as open source code in the github.com/groktopus/artifact-pyramids repo. Each can be adopted as an optional OKF convention without breaking anything.
1. In-body SOURCES sections that serve navigation and provenance simultaneously#
OKF uses markdown links between concepts, which is fine for human readers. But an agent deciding whether to load a file needs to know what it will find before it pays the context cost. A link to tables/customers.md could contain a schema definition, a PII compliance notice, a join map, or all three. The agent has to load the file to discover which.
The Artifact Pyramid solves this with a mandatory SOURCES section in the body of every file. Each entry is a path to another file in the bundle paired with a description that answers the agent’s question before it loads:
SOURCES (LAYER 2 NAVIGATION)
research/analysis/market-position.md
-> Competitor mapping and market share analysis supporting Section 2
research/analysis/technical-feasibility.md
-> Architecture evaluation supporting Section 3
research/dossiers/competitor-profiles.md
-> Raw competitor data dossiers
The description is not optional. It is the progressive disclosure mechanism in practice. The agent reads the hint, decides whether the file is relevant to its role, and loads only what passes the relevance test. The context cost of the decision is zero. The hint is in the file the agent already loaded.
Critically, this same mechanism serves provenance. The SOURCES section at L1 lists the L2 analysis files that support the summary’s claims. Those L2 files’ SOURCES sections list the L3 dossiers that contain raw evidence. The chain is audit-proof by construction because every file that asserts a claim also lists the files that back it up. There is no separate provenance mechanism to maintain.
This must live in the body, not in YAML frontmatter. Frontmatter can hold paths but cannot carry the descriptive context that makes progressive disclosure work: the one-line summary of what the agent will find. A path alone forces the agent to load the file to learn what’s in it, defeating the purpose.
Proposal: A conventional SOURCES body section, placed at the bottom of every file, listing internal bundle paths with mandatory one-line descriptions. Permissive consumers ignore it. Informed consumers navigate by it. (Issue #92)
2. Layer separation between synthesis, analysis, and raw input (made mandatory)#
OKF treats all concepts as peers. A type: Metric concept and a type: Playbook concept and a type: Table concept share the same structural level. An agent looking for strategic guidance has to wade through table schemas to find the playbook it needs.
The Artifact Pyramid encodes three distinct layers of knowledge:
| Layer | What it contains | Who consumes it |
|---|---|---|
| L1: Summary | Research question, key findings, implications (one file) | PM agents, executives, quick scanners |
| L2: Analysis Collection | Per-dimension files (market, competitive, technical, risk) | Domain specialists, analyst agents |
| L3: Detailed Dossiers | Source excerpts, raw data tables, transcripts, methodology notes | Validators, deep-dive agents |
The layer determines the reading depth, not the concept type. A PM agent never touches L3 because the orchestrator routes it to L1. A data architect reads only the specific L2 file relevant to their domain. This is not a search optimization; it is an architectural guarantee that multi-agent pipelines can route by role.
I believe OKF producers SHOULD adopt a layer field as a mandatory convention, not an optional one. The field takes values like concept (the current default for OKF), analysis, or synthesis. Consumers that don’t understand the field treat everything as concept. Consumers that do understand it route differently by layer. A bundle without layer annotations is still valid OKF, but it surrenders the multi-agent routing efficiency that the annotation enables. (Issue #93)
3. Inline citations coupled directly with claims, not separated into reference sections#
OKF’s # Citations section is a separate block at the bottom of a concept file. This works for academic citation conventions but breaks the coupling between a claim and its evidence. A reader (human or agent) encountering a claim must scroll to the bottom, find the citation, and mentally map it back to the claim.
The Artifact Pyramid requires citations inline on the claim text itself: [the specific claim](https://source.url) rather than claim text ([source](url)). The link is on the thing that needs evidence, and it reads as part of the sentence. When a SOURCES entry in an L1 summary points to an L2 analysis file, that is also an inline reference, but at the file level rather than the sentence level.
The combination of inline citations (claim-level evidence) and SOURCES sections (file-level provenance) means every assertion in every file traces concretely to its support. There is no orphaned claim. There is no footnote to chase.
Proposal: Adopt inline citation as the default convention in OKF concept bodies. The # Citations section remains available for grouped references, but the primary evidence for any claim is the hyperlink embedded in the claim itself. (Issue #94)
4. Quality gates that govern movement between layers#
OKF’s permissive consumption model accepts any content at any quality level. This is the right policy for an interchange format: you cannot reject someone else’s bundle because their frontmatter is sparse. But when knowledge moves from L3 (evidence) toward L1 (synthesis), something needs to verify that the claim at each layer is supported by the evidence beneath it.
The Artifact Pyramid enforces directional quality gates. Material moves from dossiers to analysis to summary only when it meets the standard for the target layer. The gate criteria are specific and falsifiable: every summary claim links to an analysis file, every analysis claim links to a dossier, every dossier has a source URL or transcript. A claim that cannot trace to evidence at the layer beneath it does not move up.
The mechanism for this is the SOURCES section combined with inline citations. A summary file whose SOURCES section points to L2 files that don’t exist yet is an incomplete summary. An analysis file with claims that have no inline URL is an incomplete analysis. The gate is enforced by the structure itself, not by a separate validation pass.
Proposal: Adopt a convention that a file at layer analysis must have a SOURCES section pointing to at least one file at layer concept or dossier. A file at layer synthesis must have a SOURCES section pointing to at least one analysis file. Producers who violate the convention still produce valid OKF, but pipeline orchestrators can reject bundles that don’t meet the routing contract. (Issue #95)
5. Metadata hints that help agents orient themselves before reading#
OKF models domain knowledge. But the same format is increasingly used for a different purpose: documenting what an agent accomplished as proof of work that downstream agents and humans need to validate.
The Artifact Pyramid serves as the standard output format for every specialist profile in my agent workflow. When a researcher finishes analyzing a subject, the output is an artifact pyramid at a known path. The L1 summary tells a product manager what they need to know. The provenance chain lets a verifier audit every claim. The pyramid is both the deliverable and the audit trail in one structure.
OKF has no equivalent concept. A bundle of domain concepts cannot easily serve as a task deliverable because the concepts describe what is true, not what an agent discovered or decided.
I do not think OKF should add new type values for this. The unregistered type field is one of its best features, and forcing values like type: Analysis or type: Discovery would create the governance problem OKF wisely avoids. Instead, producers should add metadata hints that help an agent orient itself: a purpose field describing why this bundle exists, a task field naming the agent task that produced it, or an audience field naming the intended consumer role. None of these are required by the spec. All of them help an agent decide whether to read the bundle without parsing it first.
The Agent Skills format provides a useful reference here. Each skill’s description field serves exactly this orientation function: a short string that tells an agent whether to load more. OKF bundles could adopt a similar description field at the bundle level (in the root index.md frontmatter) and at the concept level (in individual file frontmatter) that serves the same orienting purpose. OKF already has description as an optional frontmatter field; the gap is using it consistently for agent orientation rather than human skimming. (Issue #96)
6. Recursive gap analysis as production methodology, with reference examples#
OKF is a format. It intentionally does not specify how to produce knowledge. The spec says nothing about when a bundle is complete, how deep to go on a given topic, or when to stop adding concepts.
The Artifact Pyramid provides a repeatable production methodology: recursive gap analysis. The producer writes the L1 summary first, embedding SOURCES links to L2 analysis files that should exist. Then writes each L2 file, embedding SOURCES links to L3 dossiers that should exist. Then evaluates gaps against three criteria: is this gap in scope per the mission brief? Would filling it change any claim at the layers above? Does it add depth or just bulk? The answer determines whether another recursion round is warranted.
The methodology produces bundles whose depth matches the research’s actual information density, not a template. A simple brief produces a summary and two analysis files. A competitive landscape produces all three layers with multiple files per layer. The pyramid is as deep as the sources warrant and no deeper.
The Agent Skills specification provides the closest existing reference for this kind of progressive disclosure production model. A skill’s metadata and full instructions follow the same pattern: load the map, then load the territory only when needed. The OKF spec’s appendix could include a worked example showing an OKF producer applying recursive gap analysis to decide when a bundle is complete, using the same progression the Agent Skills standard already documents.
Proposal: Add a non-normative appendix to the OKF spec with a worked example of recursive gap analysis. Reference the Agent Skills standard’s progressive disclosure model as prior art. No spec changes needed; this is production guidance that makes the format more useful without constraining how anyone uses it.
Every file in an OKF bundle should carry a POSIX timestamp. Not as a snapshot: true/false boolean: we cannot know at any moment whether a static bundle will remain static, because newly surfaced information could change the original assumptions. A timestamp makes no such claim. It records when the file was last modified. The consumer decides what staleness means for their use case.
The timestamp field in OKF’s frontmatter schema is already optional. The proposal is to make it recommended at the concept level and mandatory at the bundle level (in the root index.md). A bundle with a root timestamp tells consumers: “this collection of knowledge was current as of this date.” Individual concept timestamps let consumers detect which parts of a bundle are stale without loading every file. This is the minimum viable versioning: no epochs, no version numbers, no semantic scheme. Just a clock.
Proposal: Elevate timestamp from optional to recommended for concepts and mandatory in the bundle root index.md frontmatter. Consumers use it for staleness detection and caching strategy. Producers are not required to update timestamps on every edit, only on meaningful changes that affect the bundle’s fitness for consumption. (Issue #97)
The Bridge#
None of these proposals requires an OKF spec change. The permissive consumption model that makes OKF portable across organizations also makes it extensible by convention. A producer who wants SOURCES sections or layer frontmatter can add them today. A consumer who doesn’t understand them ignores them. The bundle remains valid OKF either way.
And here is the practical pay-off: an Artifact Pyramid output is already structurally an OKF bundle at the filesystem level. Every file has frontmatter. The directory hierarchy is organized by depth. Cross-links navigate between layers. The only difference is the frontmatter schema (the Artifact Pyramid uses richer field names) and the navigation mechanism (SOURCES sections instead of bare markdown links). A format adapter (a script that normalizes frontmatter and generates a root index.md with okf_version: 0.1) would convert any Artifact Pyramid output into a fully conformant OKF bundle in seconds.
I built a prototype of that adapter into the open source skill. It ships with a validation script that checks OKF conformance, a concept template that produces spec-compliant frontmatter, and an example bundle that passes OKF validation. The skill is MIT licensed, installable in any Agent Skills-compatible harness, and designed to work alongside whatever OKF-compatible tools teams choose to adopt.
The Pattern Is Real#
The convergence between OKF and the Artifact Pyramid is not a coincidence. Both descend from the same intellectual lineage, but at different points in the timeline. I have been iterating on a molecular notes methodology in Obsidian for a couple of years now: atomic claims organized into molecules, cross-linked, fronted with YAML metadata, structured for recombination. Karpathy’s LLM wiki gist, which OKF formalizes, is the more recent expression of a pattern I had already been building with. Each adapts the Zettelkasten lineage for an AI-native context, but my version had years of practice before the format discussion caught up.
Google and I arrived at the same structural insight within weeks of each other, from different starting problems. That is evidence that the pattern is real. It is not an artifact of anyone’s design process. It is the shape that agent knowledge naturally wants to take.
What happens next is up to the community. OKF has a spec, a reference implementation, and the weight of Google Cloud behind it. The Artifact Pyramid has a shippable agent skill, production testing across real multi-agent pipelines, and six conventions that thirty days of use have proven out. Neither is complete without the methodology the other provides. And the best outcome is not one absorbing the other; it is both converging deliberately, the way they already converged by chance.
The repo is at github.com/groktopus/artifact-pyramids. The conventions described here are already implemented. Try them. Break them. Tell me what I missed.