
Last year I wrote about the vibe coding paradox. The tension at its core was unresolved: AI tools were generating more code than anyone could evaluate, and the people using them were losing the ability to tell good output from bad. The anxiety in those comments was real. “Mountains of broken slop.” That phrase stuck with me.
The slop is real. But it is not inevitable, and it is not a model quality problem. It is an AI workflow QA problem. Companies are shipping AI into production without any systematic way to measure whether the output is correct, helpful, or safe. They are running on vibe checks. And the industry is starting to treat this as normal.
In software, we call this kind of workflow QA an evaluation. An evaluation is a structured test that checks whether an AI output is correct, helpful, or safe: a unit test for systems that produce different output from the same input. Without evaluations, you cannot distinguish a working system from a broken one. You are guessing.
Guessing is expensive. Kanupriya Yakhmi, a former Waymo systems architect and AI/ML PhD candidate, called evaluation gaps “the most expensive form of technical debt” in a talk I covered in my piece on AI portability. A team that ships without evaluation accumulates a liability that compounds faster than code debt, because it is invisible until production failure. You do not know your eval gap exists until a customer finds it for you.
But evaluation does not have to be expensive, complicated, or slow. There is a four-rung ladder that takes you from nothing to a working evaluation pipeline. Each rung is a concrete, buildable thing. You can start today with a single test case and a Python library.
The Four-Rung Eval Ladder#
OpenAI’s evaluation best practices guide defines four types of evaluation, and they form a dependency chain rather than a menu of alternatives. Code-based checks catch what is broken. Human evaluation defines what good looks like. LLM-as-a-judge scales that definition to cover your whole output surface. User evaluation validates that your definition matches what real people actually need.
Skip a rung, and everything above it rests on an assumption you cannot verify.
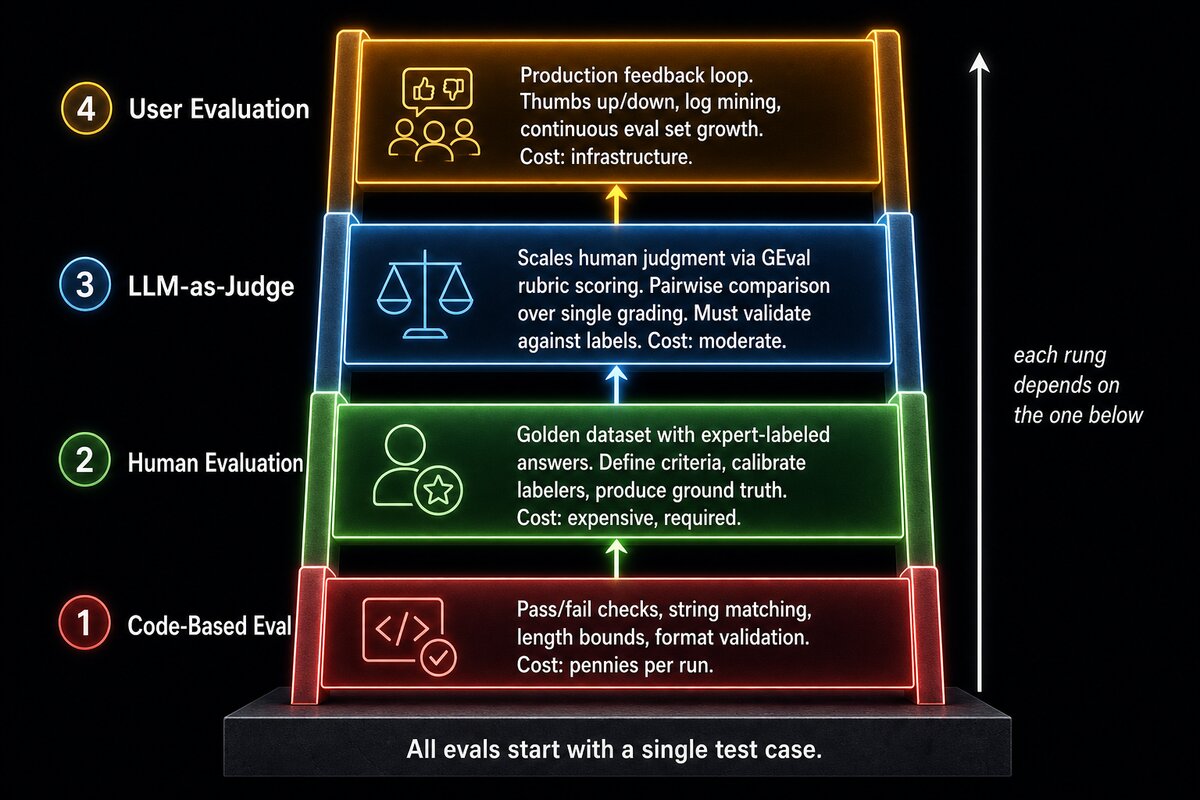
Rung 1: Code-Based (the cheapest fix you are not running)#
The simplest evaluation is a pass/fail check. Is the output too short? Too long? Does it contain a banned phrase? Does it mention a competitor? These are not sophisticated, but Peter Yang’s practical guide demonstrates that they catch the most common failures before they reach a human reviewer.
A string-matching check costs pennies per run. A length-bound check costs nothing. Yet most teams I talk to have none of these in place. Their AI “quality” process is: deploy, wait, see who complains.
Tools like DeepEval make this trivial. A single test file with a GEval metric (a criteria-based LLM-as-a-judge) gives you a pass/fail gate on every output. pip install deepeval, write a test case, run deepeval test run. That is your first eval.

Rung 2: Human Evaluation (the foundation that everything else depends on)#
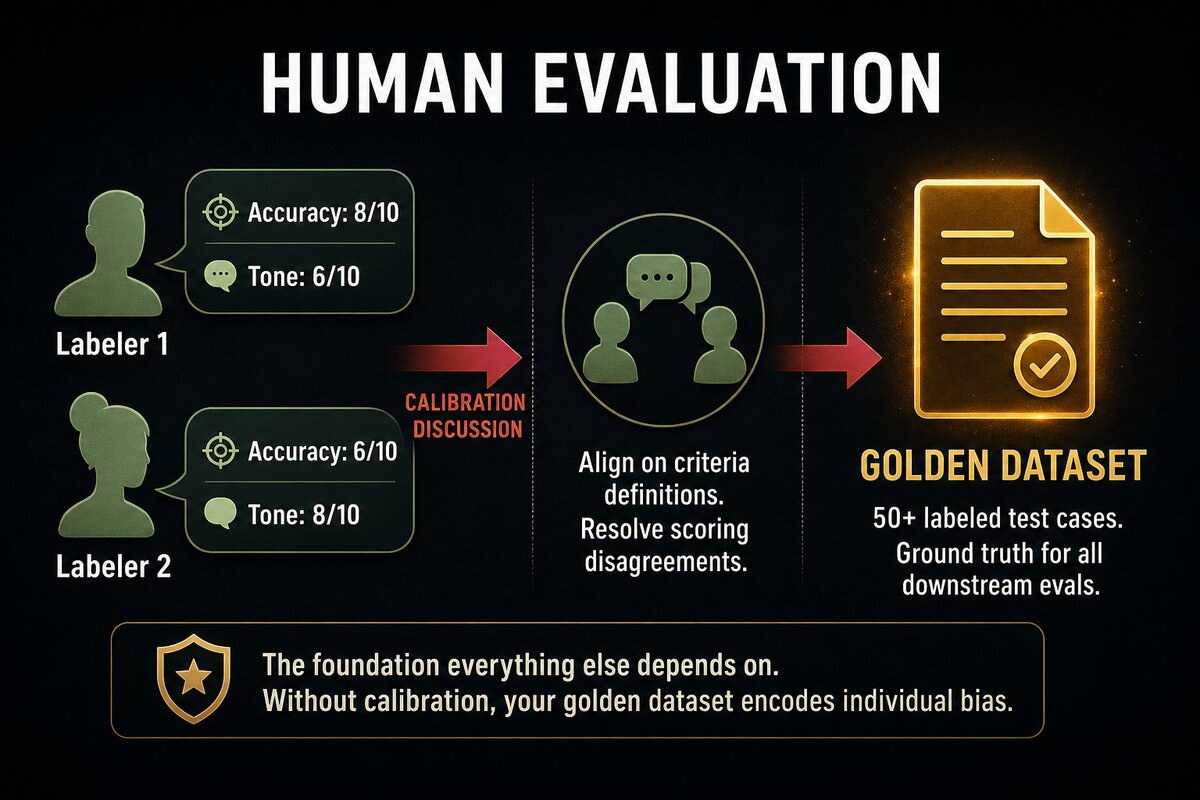
Code checks catch format violations, but they are useless for wrong answers. That gap is where human judgment comes in. You need a structured dataset with expert-labeled responses scored against explicit criteria.
OpenAI’s guide frames this as the golden dataset: a set of questions with expert-labeled answers scored against explicit criteria. Peter Yang’s walkthrough shows the full workflow. Define 3-5 criteria with clear rubrics. Generate test cases across three categories: common scenarios, edge cases, and adversarial inputs. Have multiple labelers score each response independently. Calibrate through discussion until the labelers agree on what “good” means. Then use that labeled data to train everything above it.
The calibration step is the one most teams skip, and it is the one that makes the dataset valuable. Without calibration, your golden dataset encodes individual bias rather than shared standards. Two labelers who disagree on whether a response is “helpful” or “evasive” will produce training signals that pull your LLM judge in opposite directions.
This is the expensive part. It is also the part you cannot skip. Ragas, an open-source evaluation framework, provides metrics that align with human judgment across RAG pipelines, agents, and workflows. But the metrics are only as good as the human labels they were calibrated against. The dataset comes first.
Rung 3: LLM-as-a-Judge (scaling human judgment without losing it)#
Once you have a labeled dataset, you can train an LLM judge to evaluate output at machine speed against the same criteria your human labelers used. This is where the cost curve bends.
DeepEval’s GEval metric implements the G-Eval framework from the Liu et al. 2023 paper. It uses chain-of-thought reasoning to evaluate output against custom criteria, then normalizes the score using token probabilities. The result is a 0-1 score for any criteria you define, with a reason string explaining the judgment.
from deepeval.metrics import GEval
from deepeval.test_case import SingleTurnParams
correctness_metric = GEval(
name="Correctness",
criteria="Determine whether the actual output is factually correct based on the expected output.",
evaluation_steps=[
"Check whether the facts in 'actual output' contradicts any facts in 'expected output'",
"Heavily penalize omission of detail",
"Vague language or contradicting opinions are OK"
],
evaluation_params=[SingleTurnParams.ACTUAL_OUTPUT, SingleTurnParams.EXPECTED_OUTPUT],
)
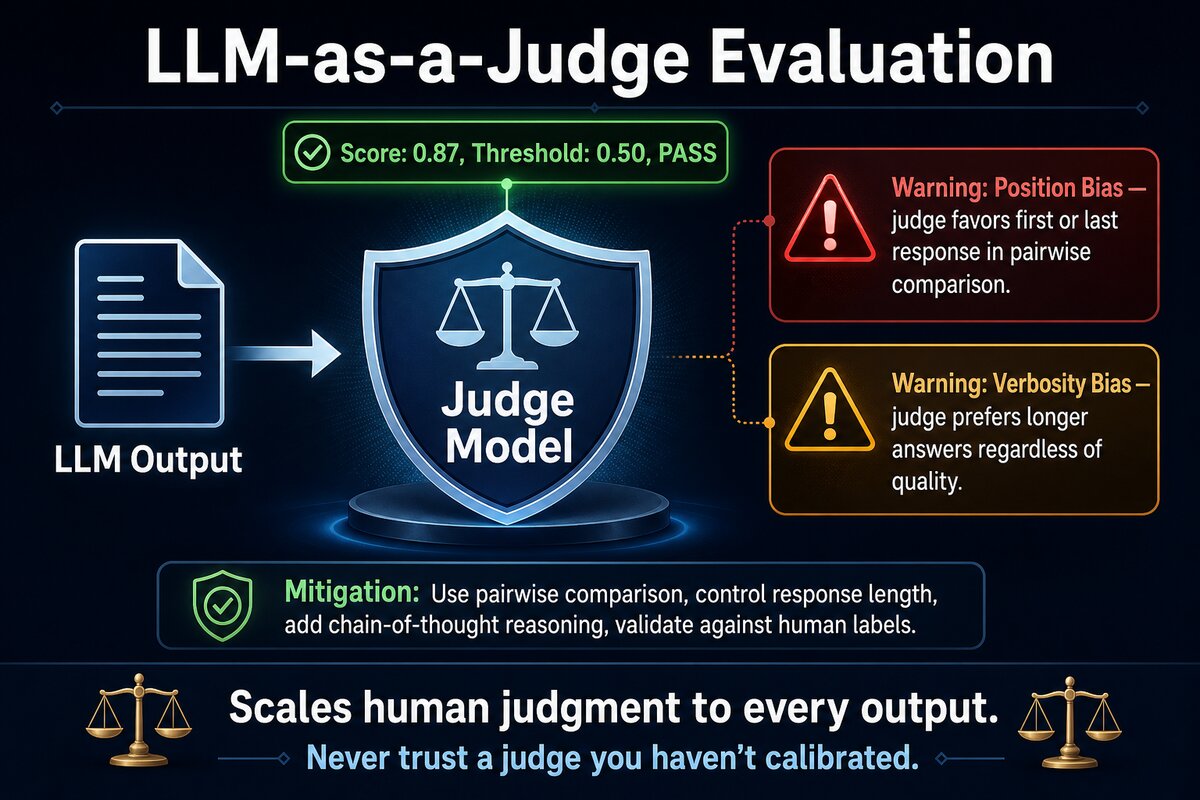
But LLM judges inherit biases, and the same OpenAI guide that recommends them also warns about them. Position bias makes a judge favor whichever response appears first or last in a pairwise comparison. Verbosity bias makes it prefer longer answers regardless of quality. The fixes are straightforward: use pairwise comparison over single-answer grading, control for response length, add chain-of-thought reasoning, and most critically, validate agreement against human labels before trusting the judge at scale.
The validation step is critical. An LLM judge that disagrees with your human labelers 30% of the time is not a judge. It is a random number generator with expensive prose. Ragas offers an “Align LLM as a Judge” workflow specifically for this calibration step.
Rung 4: User Evaluation (the loop that keeps evals honest)#
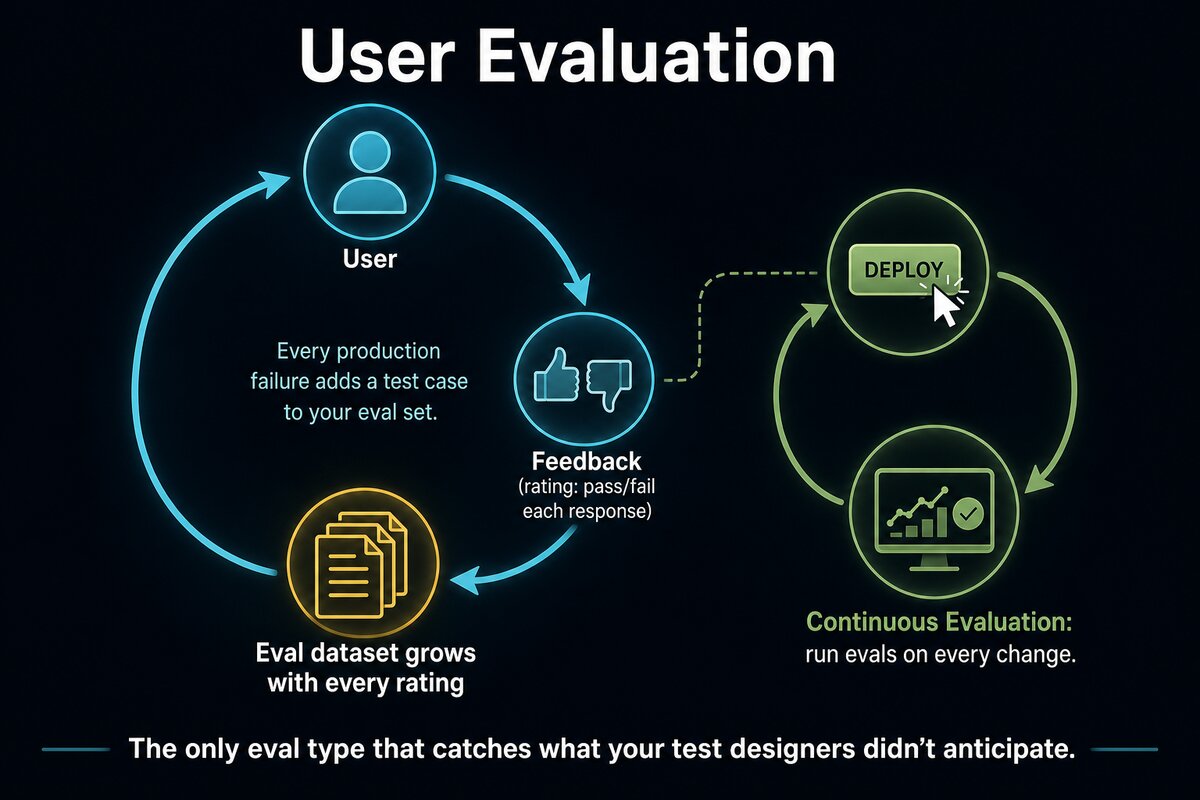
Human evals and LLM judges test against a static dataset. User evaluation tests against the real world. That is the only rung that catches what your test designers did not anticipate.
This does not require a complex platform. A feedback widget, a thumbs-up/thumbs-down on each response, and a weekly review of the bottom 5% of rated outputs. The pattern is the same one OpenAI recommends for continuous evaluation: set up monitoring on every change, log everything, and mine your logs for new test cases. Every production failure should add a row to your eval dataset. If you are not growing your eval set, it is decaying.
The Architecture Ladder Runs Parallel#
The four eval rungs are independent of architecture, but your architecture determines where nondeterminism enters the system and therefore where you need to evaluate.
OpenAI’s guide breaks this down by architecture complexity:
- Single-turn interactions are the simplest case. One input, one output. You need instruction-following and functional correctness checks.
- Workflows chain multiple model calls together. Each step in the chain needs evaluation in isolation, because a failure in step one poisons everything downstream.
- Single agents add tool selection to the eval surface. You are not just checking whether the response is correct anymore. You need to verify the right tool was called with the right arguments.
- Multi-agent systems add agent handoff accuracy. The triage agent needs to know when to hand to the order agent, and the order agent needs to know when to hand back. This is a qualitatively new failure mode that most evaluation frameworks do not address. DeepEval’s tracing supports component-level evaluation across agents built with LangChain, LangGraph, CrewAI, OpenAI Agents SDK, and Google ADK.
The rule of thumb is simple: do not add architectural complexity faster than your eval capacity. If you cannot evaluate your single-agent system, adding a second agent does not make you more capable. It makes you less measurable.
What to Build Monday Morning#
You do not need an eval platform. You need three things:
A dataset. Ten test cases spanning common, edge, and adversarial scenarios. Labeled by a human against three criteria.
A judge. One LLM-as-a-judge metric calibrated against your labels. DeepEval GEval or Ragas, whichever fits your stack.
A baseline. Run your model against the dataset, record the scores. Now you know where you stand. Every change from here on gets compared against this baseline. If the score drops, you catch it before it ships.
That is the minimum viable eval pipeline. It costs some engineering time and nothing in infrastructure. It catches regressions that would otherwise reach production. It gives you a number to point at when someone asks “is the AI working?”
The alternative: deploying on vibe checks, waiting for customers to find your failures, accumulating eval debt until a production incident forces the conversation. That is more expensive. It is always more expensive. The cost is just invisible until you add the eval.
I have watched teams burn months of engineering time on AI projects that shipped without evaluation and the organization quietly deprecated them after nobody could tell if they were working. The slop was not a model failure. It was a management failure to demand measurement before deployment.
Do not let your eval gap compound. Start with one test case, one metric, one baseline. That is how you stop the slop.
What is the worst production failure you have caught, or missed, because you had no way to tell if the AI was working? I would love to hear it.