
How MeshCore Scales Where Other LoRa Meshes Hit Walls#
The Problem: LoRa Mesh Scaling Is Not Incremental#
LoRa radio is a shared, narrow medium. The North American MeshCore preset uses 62.5 kHz of bandwidth, roughly the width of a single FM radio station. Every packet your node sends occupies that medium for everyone else within range. The physics is inescapable: more nodes means more contention, and at some point the network chokes on its own traffic.
The default approach where every node relays everything works beautifully at small scale. Five friends on a hike? Flawless. A neighborhood watch of 20 nodes? Mostly fine. But above about 50 active nodes in a single collision domain, the exponential chatter overwhelms the medium. Retransmissions collide with other retransmissions. The network slows to a crawl. Adding more nodes makes it worse, not better.
This isn’t a hardware problem. It’s an architectural one. And MeshCore solves it not with faster radios or better antennas, but with a fundamentally different set of assumptions about what a mesh network is.
The Architectural Bet: Repeaters Are Infrastructure, Not Clients#
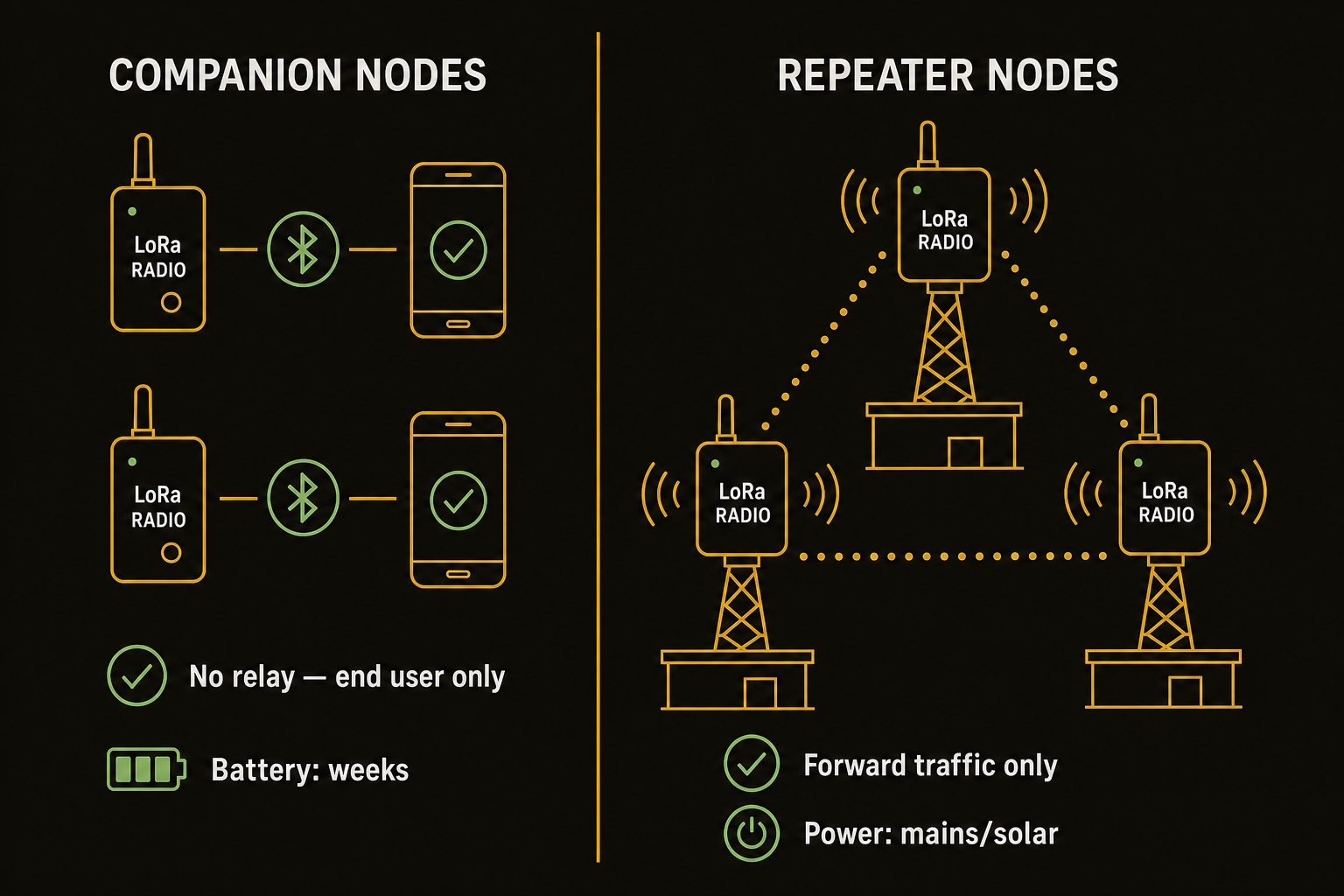
MeshCore’s deepest design decision is invisible to new users: the default node role is “companion”; it does not relay traffic. Only explicitly configured repeaters forward packets.
This is the opposite of Meshtastic, where every node relays by default. That sounds like a limitation, but it’s the entire reason MeshCore scales.
The architecture creates a clean separation:
- Companion layer: Smartphones paired to LoRa radios via Bluetooth. These are the end-user devices. They send and receive messages but never relay other people’s traffic. Battery life measured in weeks because they only listen when they need to.
- Repeater layer: Fixed infrastructure, devices mounted on towers, rooftops, and ridgelines. These are the only nodes that forward packets. They are powered continuously (mains or solar) and designed to be always-on.
This separation means network capacity scales with infrastructure investment, not user adoption. Add 100 new companion users to a MeshCore network and you add zero relay traffic. Add 100 new Meshtastic nodes to an existing network and you get 100 new potential relays, each rebroadcasting every packet they hear, squared.
Flood-Then-Direct: The Routing Innovation#
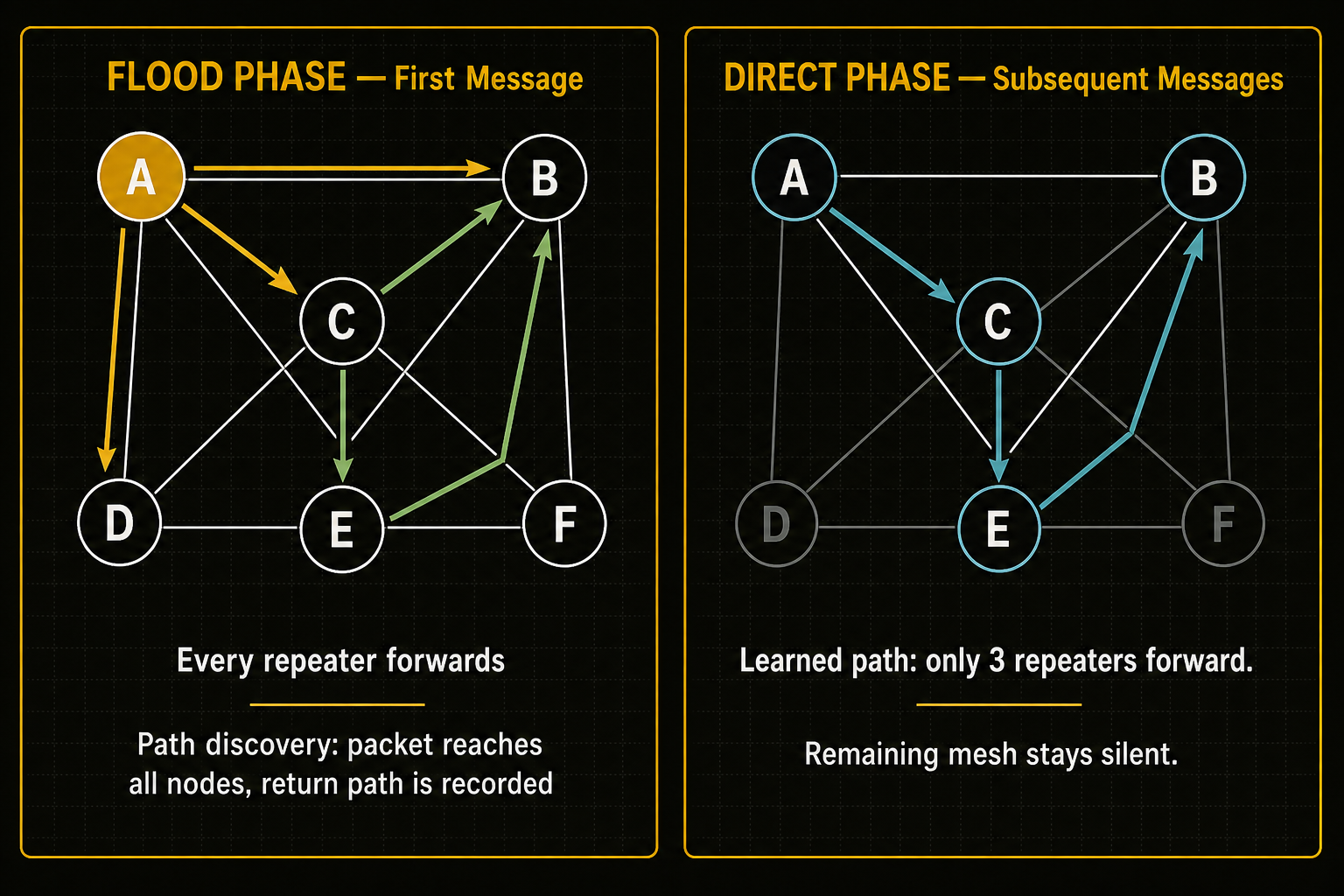
MeshCore’s routing is best described as “direct paths when possible, flood as fallback.” The protocol specification learns the network topology rather than assuming every message needs to reach every node.
Here’s how it works:
Path discovery: Alice sends a message to Bob. The packet floods through the network; every repeater forwards it until it reaches Bob or exceeds the hop limit. Each forwarder records its position in the path.
Path learning: Bob’s response includes a copy of the working path. Alice’s repeater and Bob’s repeater both memorize the route. This takes the form of a path hash, a compact 1-3 byte identifier per hop that fits in the minimal packet header.
Direct routing: Every subsequent message between Alice and Bob uses the learned direct path. Only the repeaters on that specific route forward the packet. The rest of the network hears nothing and stays silent.
Graceful fallback: If the learned path breaks (a repeater goes offline, topology changes), MeshCore detects the failure, reverts to flood mode, and learns a new path. The transition is transparent to the user.
The airtime savings are enormous. In a 50-repeater network, a single flood reaches all 50 nodes. A direct message reaches 3-5. For a conversation of 10 messages, flood-then-direct uses ~60% less airtime than flooding every message.
Why Meshtastic can’t do this: Meshtastic’s routing is managed flood. Every node rebroadcasts every message, with duplicate suppression and TTL limits. There’s no path learning. The design is simpler, more robust for ad-hoc mobile groups, and requires no infrastructure planning. But it hits a hard scaling ceiling because every message touches every node in range, every time.
The Packet Structure: Engineered for a Narrow Pipe#
Every byte matters on a 62.5 kHz channel. MeshCore’s packet format reflects this:
| Field | Size | Purpose |
|---|---|---|
header | 1 byte | Route type (2 bits), payload type (4 bits), payload version (2 bits) |
transport_codes | 0-4 bytes | Region scope identification (transport routing only) |
path_length | 1 byte | Encodes hash size + hop count |
path | up to 64 bytes | Hop-by-hop route hashes |
payload | up to 184 bytes | Encrypted message data |
Maximum packet size is about 250 bytes, deliberate discipline for a narrow-band channel. The header packs three fields into a single byte. This is not optimization for its own sake; it’s the difference between fitting a message in one transmission window and needing two.
The path encoding is particularly clever for scaling. path_length encodes both the hash size (1, 2, or 3 bytes per hop) and the hop count in a single byte. This allows a 64-hop path with 1-byte hashes or a 21-hop path with 3-byte hashes, depending on network size. Larger networks use larger hash sizes to avoid collisions. The tradeoff is path bytes vs. path capacity, and the operator chooses.
Deep dive: path hash modes and when to use them
| Mode | Hash Size | Max Hops | When to Use |
|---|---|---|---|
| 0 | 1 byte | 64 | Default. Sufficient for most regional networks. 256 possible hash values per hop. |
| 1 | 2 bytes | 32 | Networks approaching ~200 repeaters where 1-byte hash collision risk increases. |
| 2 | 3 bytes | 21 | Very large networks (500+ repeaters) or when trace routes show hash collisions. |
All repeaters on a mesh must agree on path hash mode; a mixed-mode network produces unresolvable paths. Upgrade only when the majority of regional repeaters are running firmware v1.14+. See the MeshCore CLI reference for path.hash.mode configuration.
The 15 payload types include some unexpected but useful ones: TRACE collects per-hop SNR reports for link debugging, MULTIPART enables segmented messages for content that exceeds the 184-byte payload limit, and CONTROL handles unencrypted network management packets. This is a protocol designed for diagnostics and operations, not just messaging.
Traffic Shaping: The Timing Toolbox#
Flood-then-direct routing doesn’t magically eliminate contention; it needs careful timing to prevent multiple repeaters from shouting over each other. MeshCore provides four knobs for this, and understanding them is the difference between a network that hums and one that stutters.
The Three-Tier TxDelay System#
The most important timing parameter is txdelay. It controls how long a repeater waits before forwarding a received packet. The community, particularly Eric Hendrickson (W6HS), has converged on a three-tier system:
The effect is a deliberate propagation cascade: local repeaters fire first (they’re closest and most relevant for nearby delivery), regional nodes follow (catching packets that need wider distribution), and backbone nodes fire last (providing wide-area bridging only for packets that actually need it). This prevents a mountain-top repeater from “talking over” a ground-level repeater that’s already handling the local delivery.
The Full Parameter Cascade#
The four timing parameters work in sequence:
flood.max(hop limit, default 64). TTL check first. If the packet has exceeded its allowed hops, it’s dropped before any timing logic runs.rxdelay(SNR-based stagger). Weaker signals wait longer. This ensures the strongest, most reliable path propagates first. A backbone node receiving a packet at SNR +12 dB forwards before one receiving it at SNR +3 dB.txdelay(role-based stagger). Layer in the three-tier hierarchy. After rxdelay selects the best path, txdelay ensures the right tier of repeater forwards at the right time.af(airtime factor, deprecated v1.15+). A global timing multiplier for fine-tuning at congested choke points. Now replaced by more precise per-parameter control.
A well-tuned backbone repeater “cooperates in but does not dominate the mesh.” It waits long enough for local nodes to handle nearby delivery, then provides wide-area coverage only for packets that need to travel further.
MeshCore vs Meshtastic: The Architectural Comparison#
The two platforms occupy fundamentally different design spaces. Here’s the head-to-head:
Real-World Evidence: Do the Networks That Exist Match the Theory?#
Theory is one thing. Let’s look at the networks that are actually running at scale.
Pacific Northwest Corridor (~1,000 nodes)#
The most mature MeshCore regional network spans from Vancouver, BC to Eugene, OR, over 200 km of coverage. The architecture follows the hybrid approach: meshed backbone clusters in Seattle and Portland, linked by corridor repeaters along the I-5 corridor. The network has been running since early 2025 and consistently demonstrates multi-hop message delivery with sub-minute latency at 200+ km range. See the MeshCore community map and Pacific Northwest corridor discussions on Reddit.
Key lesson: the corridor approach works. A linear backbone with redundant mesh clusters at population centers provides wide-area coverage at lower infrastructure cost than a full-area mesh.
LocalMesh Netherlands (800+ repeaters)#
The Netherlands network is the densest MeshCore deployment documented, with over 800 repeaters covering the entire country documented by LocalMesh. It demonstrates that MeshCore’s timing parameters and region filtering can scale to national-level density. The key enabler: consistent configuration across all repeaters (matched af settings, coordinated txdelay tiers, well-planned region boundaries).
Key lesson: density is manageable with disciplined configuration. The Netherlands network proves that MeshCore doesn’t break under weight; it just requires the operator community to agree on settings.
RDUMesh (16 counties, North Carolina)#
Our regional network, RDUMesh, in the North Carolina Piedmont demonstrates the mid-scale pattern: over 200 repeaters across 16 counties, anchored by high-site repeaters at amateur radio club towers and tall buildings in Raleigh and Durham. The Eastern Repeater at 110m AGL with a 9.3 dBi Diamond BC920 provides the backbone bridge between the Raleigh metro and eastern NC. See the RDUMesh network map for current node positions.
Key lesson: amateur radio tower sites provide the lowest-friction path to high-elevation repeater placement. The existing infrastructure of ham radio clubs (towers, power, shelter, maintenance access) maps directly onto MeshCore backbone requirements.
The Bottom Line#
MeshCore scales because it made deliberate architectural bets that Meshtastic, by design, did not:
- Bet 1: Not every node needs to relay. Separate the infrastructure layer from the user layer.
- Bet 2: Path learning saves exponentially more airtime than it costs. Flood once, route directly forever.
- Bet 3: Timing discipline beats raw retransmission. A well-timed backbone cascade delivers more messages per channel-hour than aggressive flooding.
- Bet 4: Narrow bandwidth is an asset, not a liability. 62.5 kHz of disciplined throughput outperforms 250 kHz of noise in dense environments.
The tradeoff is real: MeshCore requires planning. You can’t throw a MeshCore repeater in a backpack, hike into the woods, and expect it to mesh with strangers passing by the way you can with Meshtastic. MeshCore rewards infrastructure investment and coordinated deployment. Meshtastic rewards spontaneity and mobility.
If you’re building a regional resilience network, a civil defence communication system, or a permanent mesh for your community: MeshCore is the technical answer. The networks that exist at scale prove it.
If you want to message your friends on a group hike this weekend: use Meshtastic. Different tools, different jobs.
Thanks to Eric Hendrickson (W6HS), Scott Powell, Liam Cottle, and the MeshCore community for the documentation and analysis that informed this piece. Network data from LocalMesh, meshcore.io, and community deployment reports on Reddit and Discord.